import matplotlib.pyplot as plt
# Plot the transformed data
plt.scatter(tsne_features_leg[:,0], tsne_features_leg[:,1], alpha=0.5)
plt.show()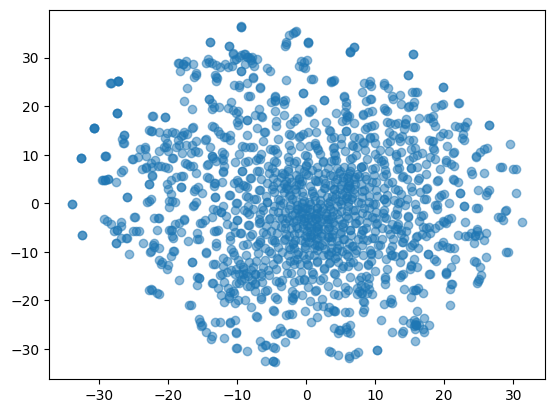
This notebook is aimed to satisfying the requirements of the Final Learning Assessment Activity for the course TÓPICOS AVANÇADOS EM INTELIGÊNCIA COMPUTACIONAL 2, which is part of the Masters Degree in Computer Intelligence in Instituto Metropole Digital - IMD.
It consists in the application of one or more of the techniques presented throughout the course, in the field of Natural Language Processing - NLP.
As suggested in the guidelines of the activity, we are going to explore a set of data with content which is public - or widely available on the web. Due to reasons more thoroughly addressed in sessions below, we are going to make use two datasets, both with textual documents, namely: (1) a set of documents which are part of the state legislation texts from Assembleia Legislativa do Rio Grande do Norte (one of the Brazilian Federal Union), and (2) an artificial corpus of documents from a few different fields.
Neither of these datasets are readily available, being, rather, created duting this study. The legislation documents are more organic, while the other corpus was created only for the purposes of this work. They are both explained below.
In the website of Assembleia Legislativa do Rio Grande do Norte - ALRN, there is a specific page which makes it possible for the citizens to access the text of the laws and regulations produced by the body of State Representatives in Rio Grande do Norte, Brazil. We are going to use this specific dataset to practice the techniques studied in the course, as well as to evaluate its quality for a possible broader study. This dataset was meant to be the main (rather the only) dataset to be used in this notebook. However, for reasons yet to be explained, it was necessary the already mentioned second dataset.
In this page, there is a list of links to download all of the documents available. Those links were accessed, their contents were downloaded and processed as follows:
We accessed the source code of the page and scraped the 5493
links in the html page (on october/31/2023), saving them in a file
(Lista_Leis.txt). The number of documents seemed
promissing.
A python script was used to try to download all of files in the link list. The result is recorded in the following files:
- log.txt: log of urls whose attempt to save resulted in an error
- Urls_Baixadas.txt: list of urls with successful download
- Urls_Nao_Encontradas: list of urls with 404 error
Of the total of 5493 links, only 2744 pointed to files that were actually available
The text of the 2744 documents was extracted using another python
script (pyscript_processamento_pdf.py), heavily based on
the pypdf library.
After the extraction, only 2268 out of the 2744 total had textual
content (listed in arquivos_com_conteudo.txt).
Out of the remaining 2744 files, files with duplicate content
were identified with fdupes, a linux tool for detecting
duplicated files(listed in arq_duplicados.txt). The
duplicate files were removed, remaining only 1861 documents.
After some more inspection, we found out that out of those 1861
remaining documents, 52 files did not have text, being only image scans
of the original printed documents, which were read as characters that
represented the information from the images present in them. After their
elimination (listed in arq_conteudo_invalido.txt), only
1809 files remained.
The dataset has 3 pieces of information for every document (columns): (1) the name of the document as provided by the source website, (2) the url to access the document, and (3) the text extracted from the downloaded pdf file.
This dataset has the purpose to suppplement the first dataset and the conclusions which came from its analysis and limitations - which will be addressed further. We collected texts from a range of domains, prioritizing public domain/open text, as well as extensive works (in order to keep some homogeneity of style). The documents are in the following categories:
It is clear that it is a diminute dataset, if we consider each book as a document. Therefore, in order to have more samples, we did the following:
alcorao,
arduino, cervantes, cristianismo,
culinaria, nheengatu, psicologia
and python.We are aware that the classes assigned may overlap (in the case of
python and arduino), be diverse
(cristianismo may have two very different styles,
considering the heterogeneity of New and Old Testament), and also be
quite similar (the Old Testament part of cristianismo has
some style and vocabulary similarities with the Quran).
# Funtion just to draw my attention. Useful when long code is
# running an I want to do something else while ir runs.
from google.colab import output
def alert_me():
output.eval_js('new Audio("https://upload.wikimedia.org/wikipedia/commons/0/05/Beep-09.ogg").play()')from google.colab import drive
drive.mount('/content/drive')
DATA_URL = '/content/drive/MyDrive/Mestrado/PLN/leis_pickle'
import warnings
warnings.filterwarnings("ignore")Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
To start, We do the usual imports and load the data from the pickle dump
import pickle
import numpy as np
import pandas as pd
import time
import gensim
from tqdm import tqdm
from functools import partial
tqdm.pandas()
tqdm = partial(tqdm, position=0, leave=True)
with open(DATA_URL, 'rb') as afile:
rawdata_leg = pickle.load(afile)
data_leg = list(rawdata_leg)After loading the raw data, we move on to removing the non alphabetical characters, removing all the rest. We do this only in order to have it a bit cleaner to make the whole process smoother.
def clean_breaks_and_periods(text):
'''
Receives a piece of text and returns it without the line breaks
and without excessive periods
'''
text = text.replace('\n', ' ')
while ' .' in text or ' ' in text or '..' in text:
text = text.replace(' .', '.').replace(' ,', ',').replace('..', '.').replace(' ;',';').replace(' ',' ')
return text
def remove_nonalph_characters(text):
'''
Receives a piece of text and removes all of the charecters which are not
alphabetical characters - vowels with diacritics included
'''
base = "abcdefghijklmnopqrstuvwxyzàáâãäåçèéêëìíîïñòóôõöùúûü"
base += base.upper() + ';. '
output = ''
for char in text:
if char in base: output += char
else: output += ' '
while ' ' in output: output = output.replace(' ', ' ')
return output
for doc in tqdm(data_leg):
doc.append(remove_nonalph_characters(clean_breaks_and_periods(doc[2].lower())))
dataset_leg = pd.DataFrame(data_leg, columns=['doc_name', 'url', 'raw_text', 'text'])100%|██████████| 1809/1809 [00:10<00:00, 165.19it/s]
Now we process the textual contents of the document to be used futher in the process
import nltk
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words('portuguese')[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
from sklearn.feature_extraction.text import TfidfVectorizer
def create_tfidf_representation(data):
# This vectorizer will work on the whole dataset, creating a representation with TFIDF
# so We want it to disregard freatures which are common to most of the documents in the
# corpus as a whole. Therefore, we're ignoring terms persent in at least 80% of the corpus.
vectorizer = TfidfVectorizer(max_features=500,
stop_words=stopwords,
max_df=0.80)
tfidf_matrix = vectorizer.fit_transform(data)
feature_names = vectorizer.get_feature_names_out()
tfidf_scores = tfidf_matrix.toarray()
top_words_per_document = []
tfidf_filtered_doc_texts = []
for doc_idx, doc in tqdm(enumerate(data)):
# Get the indices of the top N TF-IDF scores for the current document
top_word_indices = tfidf_scores[doc_idx].argsort()[::-1]
# Extract the corresponding words
top_words = [feature_names[idx] for idx in top_word_indices]
# makes a copy of the text in the document, discarding the words
# which are contained in 'top_words'
tfidf_filtered_text = [word for word in doc.split(' ') if word in top_words]
# Store the top words for the current document
top_words_per_document.append(' '.join(top_words))
# Stores the filtered text
tfidf_filtered_doc_texts.append(' '.join(tfidf_filtered_text))
return top_words_per_document, tfidf_filtered_doc_textsdataset_leg['high_ranked_words'], dataset_leg['tfidf_filtered_text'] = create_tfidf_representation(dataset_leg['text'])1809it [00:18, 98.87it/s]
In order to better visualize the results of the clustering, we, now, have some different representations of the text:
raw_text: the verbatim content read from the pdf
files;text: the contents of raw_text, except
that cleaned for better analysis; andtfidf_filtered_text: the contents of text,
except that keeping only the most relevant words resulting from the
TfidfVectorizer.The latter will be particularly relevant for visually inspecting the data and its structure.
Now we split the dataset into Train and Test Sets
from sklearn.model_selection import train_test_split
train_data_leg, test_data_leg = train_test_split(dataset_leg, test_size=0.2, random_state=161803)After which, we preprocess the sets to be used in our model.
def gensim_preprocess(series, tokens_only=False):
for i, line in tqdm(enumerate(series)):
tokens = gensim.utils.simple_preprocess(line)
if tokens_only:
yield tokens
else:
# For training data, add tags
yield gensim.models.doc2vec.TaggedDocument(tokens, [i])
train_leg = list(gensim_preprocess(train_data_leg['text']))
test_leg = list(gensim_preprocess(test_data_leg['text'], tokens_only=True))1447it [00:04, 343.15it/s]
362it [00:00, 866.59it/s]
As can be seen, train_leg has 1447 observations, while
test_leg has 362 of them.
Let us take a look into the format of one of those instances in
train_leg. We also compare with the corresponding element
in the Dataframe train_data_leg.
train_leg[12]TaggedDocument(words=['assembleia', 'legislativa', 'do', 'estado', 'do', 'rio', 'grande', 'do', 'orte', 'secretaria', 'legislativa', 'rio', 'grande', 'do', 'norte', 'lei', 'de', 'de', 'julho', 'de', 'institui', 'dia', 'estadual', 'em', 'comemoração', 'lei', 'maria', 'da', 'penha', 'governadora', 'do', 'estado', 'do', 'rio', 'grande', 'do', 'norte', 'faço', 'saber', 'que', 'poder', 'legislativo', 'decreta', 'eu', 'sanciono', 'seguinte', 'lei', 'art', 'fica', 'instituído', 'dia', 'estadual', 'em', 'comemora', 'ção', 'lei', 'maria', 'da', 'penha', 'que', 'estabeleceu', 'medidas', 'para', 'prevenir', 'punir', 'erradicar', 'violência', 'contra', 'mulher', 'ser', 'comemorado', 'anualmente', 'no', 'dia', 'de', 'ag', 'osto', 'com', 'objetivo', 'de', 'valorizar', 'apoiar', 'realização', 'de', 'encontros', 'exposições', 'estud', 'os', 'debates', 'eventos', 'demais', 'atividades', 'relacionadas', 'família', 'mulher', 'potigu', 'ar', 'art', 'esta', 'lei', 'entrará', 'em', 'vigor', 'na', 'data', 'de', 'sua', 'ublicação', 'revogadas', 'as', 'disposições', 'em', 'contrário', 'palácio', 'de', 'despachos', 'de', 'lagoa', 'nova', 'em', 'natal', 'de', 'julho', 'de', 'da', 'independência', 'da', 'república', 'rosalba', 'ciarlini', 'rosado', 'thiago', 'cortez', 'meira', 'de', 'medeiros'], tags=[12])train_data_leg['text'].iloc[12]{"type":"string"}Now we are done with loading the dataset. We can now dive into the modelling phase.
model_leg = gensim.models.doc2vec.Doc2Vec(vector_size=100, min_count=2, epochs=40)
model_leg.build_vocab(train_leg)print("Word 'violência' appeared {} times in the training corpus.". format(model_leg.wv.get_vecattr('violência', 'count')))Word 'violência' appeared 630 times in the training corpus.
model_leg.train(train_leg, total_examples=model_leg.corpus_count, epochs=model_leg.epochs)In order to have just a preliminary overview of the performance of our model, let's assess how it goes in the following process:
We are, literally, using the natural fitting to the data used for training, so that we naturally recall, based on the vector inferred from a document, this same document. In this way, we may have an idea if it is working as it should.
ranks = []
second_ranks = []
more_than_ten_away=[]
for doc_id in tqdm(range(len(train_leg))):
model_leg.random.seed(161803) # this ensures repeatability, since Doc2Vec has no seed parameter
inferred_vector = model_leg.infer_vector(train_leg[doc_id].words)
sims = model_leg.dv.most_similar([inferred_vector], topn=len(model_leg.dv))
rank = [docid for docid, sim in sims].index(doc_id)
if rank > 10: more_than_ten_away.append((rank, doc_id))
ranks.append(rank)
second_ranks.append(sims[1])
more_than_ten_away.sort(key=lambda x: x[0])100%|██████████| 1447/1447 [01:38<00:00, 14.72it/s]
In ranks, we store the index of the doc_id
for each document in the list of similarity (which is sorted inascending
order - the lowest, the closest). Every case in which it is a zero, the
model hit it, pointing the document itself as the most similar.
In second_ranks, we are recording the second most
similar document.
In more_than_ten_away we saved all of the cases in which
the document was considered more than the tenth most similar to itself.
Just for further inspection.
In an ideal result, we would have all of the elements in
rank as zeroes and all of the results in
second_ranks are the documents with the closest similarity
to wach document in the training data.
Let's check how the model did on this task.
import collections
counter = collections.Counter(ranks)
print('############### RANKS ###############\n{}\t{}\t{}'.format('categ', '# obsv', '% Total'))
keys = list(counter.keys())
keys.sort()
for k in keys:
v = counter[k]
print('{}\t{}\t{}'.format(k, v, "{:.2f}".format(v/sum(counter.values()) * 100)))############### RANKS ###############
categ # obsv % Total
0 1293 89.36
1 43 2.97
2 18 1.24
3 6 0.41
4 8 0.55
5 4 0.28
6 5 0.35
7 4 0.28
8 3 0.21
9 3 0.21
10 1 0.07
11 3 0.21
12 2 0.14
14 3 0.21
15 4 0.28
16 2 0.14
17 3 0.21
18 1 0.07
19 2 0.14
20 1 0.07
21 1 0.07
22 4 0.28
23 3 0.21
24 2 0.14
28 1 0.07
31 1 0.07
34 1 0.07
35 1 0.07
36 1 0.07
37 1 0.07
39 1 0.07
41 1 0.07
42 1 0.07
44 1 0.07
47 2 0.14
49 1 0.07
53 1 0.07
59 1 0.07
65 1 0.07
66 1 0.07
73 1 0.07
74 1 0.07
75 1 0.07
76 1 0.07
92 2 0.14
95 1 0.07
109 1 0.07
119 1 0.07
159 1 0.07
171 1 0.07
In about 89% of the cases, the model correctly classified the closest document as itself. In a 2.5 percent of the cases, it was the second closest. Let's inspect one of these documents closely. For the sake of simplicity, let's pick the last document to be processed (so we may reuse the list of similar documents previously calculated).
print('Text of the Document ({}):\n"{}"\n'.format(doc_id, ' '.join(train_leg[doc_id].words)))
for label, index in [
('Most Similar Document', 0),
('Second Most Similar', 1),
('Third Most Similar', 2)]:
print('{} {}:\n{}\n'.format(label, sims[index], ' '.join(train_leg[sims[index][0]].words)))Text of the Document (1446):
"coordenadoria de controle dos at os govern amentai contrag gac rio grande do norte lei de de setembro de institui no calendário oficial do rio grande do norte dia estadual de combate ao feminicídio governador do estado do rio grande do no rte faço aber que poder legislativo decreta eu sanciono seguinte lei art fica instituído no calendário oficial do rio grande do norte dia estadual de combate ao feminicídio ser celebr ado anualmente em de julho art esta lei entra em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de setembro de da independência da república fátima bezerra governadora doe data pág"
Most Similar Document (1446, 0.9329580068588257):
coordenadoria de controle dos at os govern amentai contrag gac rio grande do norte lei de de setembro de institui no calendário oficial do rio grande do norte dia estadual de combate ao feminicídio governador do estado do rio grande do no rte faço aber que poder legislativo decreta eu sanciono seguinte lei art fica instituído no calendário oficial do rio grande do norte dia estadual de combate ao feminicídio ser celebr ado anualmente em de julho art esta lei entra em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de setembro de da independência da república fátima bezerra governadora doe data pág
Second Most Similar (446, 0.9115090370178223):
coordenadoria de controle dos atos governamentais contrag gac rio grande do norte lei de de outu bro de reconhece como de utilidade pública estadual instituto neném borges governador do estado do rio grande do norte faço saber que poder legislativo decreta eu sanciono seguinte lei art fica reconhecido como de utilidade pública estadual instituto neném borges com sede foro jurídico no município de são josé do campestre neste estado art esta lei entra em vigor na data de sua publicação palácio de despachos de lagoa nova em natal rn de outubro de da independência da república fátima bezerra governadora doe data pág
Third Most Similar (1136, 0.9099540114402771):
coordenadoria de controle dos atos govern amentais contrag gac rio grande do norte lei de de julho de institui no calendário oficial do estado do rio grande do norte dia estadual do doador de sangue governadora do estado do rio grande do norte faço aber que poder legislativo decreta eu sanciono seguinte lei art fica instituído no calendário oficial do estado do rio grande do norte dia estadual do doador de sangue ser celebra do anualmente no dia de novembro art esta lei entra em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de julho de da independência da república fátima bezerra governadora doe data pág
This particular document was a hit, both in being correctly classified as the closest to itself and also in having the second and third most similar documents addressing a related matter (regulation of familiar agriculture and sanitary insections in this context).
Now, let's take a look in the documents in the
second_rank for a random document in
train_leg.
# Pick a random document from the corpus and infer a vector from the model
import random
doc_id = random.randint(0, len(train_leg) - 1)
# Compare and print the second-most-similar document
print('Random Document in `train_leg` ({}):\n"{}"\n'.format(doc_id, ' '.join(train_leg[doc_id].words)))
sim_id = second_ranks[doc_id]
print('Similar Document ({}):\n"{}"\n'.format(sim_id, ' '.join(train_leg[sim_id[0]].words)))Random Document in `train_leg` (753):
"coordenadoria de ontrol dos atos governamentais contrag gac rio grande do norte lei de de setembro de reconhece como de utilidade pública entidade que especifica dá outras providências governador do estado do rio grande do norte faço sab er que poder legislativo decreta eu sanciono seguinte lei art fica reconhecida como de utilidade pública associação cultural desportiva pauferrense capoeira apcap com sede foro jurídico no município de pau dos ferros neste estado art esta lei entrará em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de setembro de da independência da república fátima bezerra governadora doe data pág"
Similar Document ((753, 0.9529330134391785)):
"coordenadoria de ontrol dos atos governamentais contrag gac rio grande do norte lei de de setembro de reconhece como de utilidade pública entidade que especifica dá outras providências governador do estado do rio grande do norte faço sab er que poder legislativo decreta eu sanciono seguinte lei art fica reconhecida como de utilidade pública associação cultural desportiva pauferrense capoeira apcap com sede foro jurídico no município de pau dos ferros neste estado art esta lei entrará em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de setembro de da independência da república fátima bezerra governadora doe data pág"
We can see that there is also a close similarity between the topics addressed in the random picked documents.
Now let's repeeat the activity, but using the Test data.
# Pick a random document from the test corpus and infer a vector from the model
doc_id = random.randint(0, len(test_leg) - 1)
# not using model_leg.random.seed(161803) because the context is random by nature.
inferred_vector = model_leg.infer_vector(test_leg[doc_id])
sims = model_leg.dv.most_similar([inferred_vector], topn=len(model_leg.dv))
# Compare and print the most/median/least similar documents from the train corpus
print('Text of the Document ({}):\n"{}"\n'.format(doc_id, ' '.join(test_leg[doc_id])))
for label, index in [
('Most Similar Document', 0),
('Second Most Similar', 1),
('Third Most Similar', 2)]:
print('{} {}:\n{}\n'.format(label, sims[index], ' '.join(train_leg[sims[index][0]].words)))Text of the Document (346):
"contrag gac lei de de março de institui disciplina meio am biente recursos hídricos no currículo das escolas da re de pública es tadual dá outras providências presidente da assembléia legislativa do estado do rio grande do norte no uso das atribuições que lhe são conferid as pelo artigo da constituição do estado combinado com artigo ii do regimento interno resolução de de dezembro de faço saber que poder legisl ativo aprovou eu promulgo seguinte lei art fica estabelecida obrigator iedade de inclusão de conteúdos sobre meio ambiente recursos hídricos nas escolas da rede pública estadual art disciplina meio ambien te recursos hídricos visa conscientizar educando sobre necessidade de preservação do meio ambiente sobre valor dos recursos hídricos do estado art esta lei entra em vi gor na data de sua publicação art revoga se as disposições em contrário assembléia legislativa do estado do rio grande do norte palácio josé augusto em natal de março de deputada larissa rosado vice presidente no exercício da presidência doe data pág"
Most Similar Document (789, 0.6042366623878479):
contrag gac rio grande do norte lei de de dezembro de reconhece de utilidade pública associação de educação cidadania santos dumont governadora do estado do rio grande do norte faço saber que poder legislativo decreta eu sanciono seguinte lei art fica reconhecida como de utilidade pública associação de educação cidadania santos dumont aesd com sede foro jurídico no município de tibau neste estado art esta lei entra em vi gor na data de sua publicação palácio de despachos de lagoa nova em natal de dezembro de da independência da república doe data pág
Second Most Similar (1352, 0.5969226360321045):
documento publicado em edição diária diariooficial rn gov br dei dorn docview aspx id jor data id doc rio grande do nor te lei de de julho de reconhece como de utilidade pública cooperativa de catadores recicladores artesãos de pureza rn crearp governadora do estado do rio grande do nor te faço saber que poder legislativo decreta eu sanciono seguinte lei art fica reconhecida como de utilidade pública cooperativa de catador es reciclad ores artesãos de pureza rn crearp com sede foro jurídico no município de pureza neste estado art esta lei entra em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de julho de da independência da república fátima bezerra governadora
Third Most Similar (21, 0.5932024717330933):
documento publicado em edição diária diariooficial rn gov br dei dorn docview aspx id jor data id doc rio grande do nor te lei de de julho de reconhece como de utilidade pública associação porto de ama centro petrobrás de cultura governadora do estado do rio grande do nor te faço saber que poder legislativo decreta eu sanciono seguinte lei art fica reconh ecida como de utilidade pública associação porto de ama centr petrobrás de cultura com sede foro jurídico no município de macau neste estado art esta lei entra em vigor na data de sua publicação palácio de despacho de lagoa nova em natal rn de julho de da independência da república fátima bezerra governadora
The test data yielded results similar to the ones obtained with the training data.
In order to better understand the relationship among the instances in the dataset, we may analyze its topology, as far as the distances among the observations are concerned.
To do so, we create a vector for each of he documents, using our Doc2Vec model.
# preparing the vectors to be used
vectors_leg = []
for doc in tqdm(train_leg):
model_leg.random.seed(161803)
vectors_leg.append(model_leg.infer_vector(doc.words))
vectors_test_leg = []
for doc in tqdm(test_leg):
model_leg.random.seed(161803)
vectors_test_leg.append(model_leg.infer_vector(doc))100%|██████████| 1447/1447 [01:09<00:00, 20.91it/s]
100%|██████████| 362/362 [00:17<00:00, 20.60it/s]
We, then, apply some dimensionality reduction, by using T-SNE. Let us reduce the vectors to 2 dimensions.
from sklearn.manifold import TSNE
# Create the model
tsne_model_leg = TSNE(n_components=2, random_state=161803)
tsne_features_leg = tsne_model_leg.fit_transform(np.array(vectors_leg))
tsne_features_test_leg = tsne_model_leg.fit_transform(np.array(vectors_test_leg))Now we can scatter-plot both the train set and the test set, and see how it looks like.
import matplotlib.pyplot as plt
# Plot the transformed data
plt.scatter(tsne_features_leg[:,0], tsne_features_leg[:,1], alpha=0.5)
plt.show()
The train set seems to be arranged in a single group, whose concentration is a gradient, with more elements bunched in the center, and getting a bit more sparse towards the edges. There are, in fact some blobs in certain parts of the distribution, but there aren't very distinctive cluster visible. Let's try a similar inspection of the test set.
# Plot the transformed data in the vector with the test set
plt.scatter(tsne_features_test_leg[:,0], tsne_features_test_leg[:,1], alpha=0.5)
plt.show()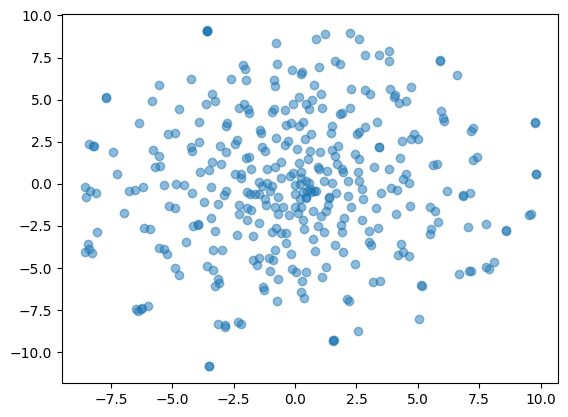
The test set seems to be arranged in the same way, except that a bit more sparse in the whole, which is a result of its number of instances, inferior to the train set.
Let's move away from mere visual inspection, and try some clustering to see what we get.
We'll use Kmeans to cluster the domensionally-reduced version of the data.
To start, with, we need to decide the number of clusters to use. We can try to use silhouette score and the elbow technique to find out the best option.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def silhouette_analysis(data, min_k=2, max_k=15, step=1):
range_num_clust = range(min_k, max_k+1, step)
silhouette_avg = []
for k in range_num_clust:
# initialise kmeans
kmeans = KMeans(n_clusters=k)
kmeans.fit(data)
cluster_labels = kmeans.labels_
# silhouette score
silhouette_avg.append(silhouette_score(data, cluster_labels))
f, ax = plt.subplots(1, 1)
ax.plot(range_num_clust, silhouette_avg, marker='o')
ax.set_xlabel('Number of Cluster Centers')
ax.set_xticks(range_num_clust)
ax.set_xticklabels(range_num_clust)
ax.set_ylabel('Silhouette')
ax.set_title('Silhouette by Cluster Center Plot')
silhouette_analysis(tsne_features_leg, min_k=2, max_k=15)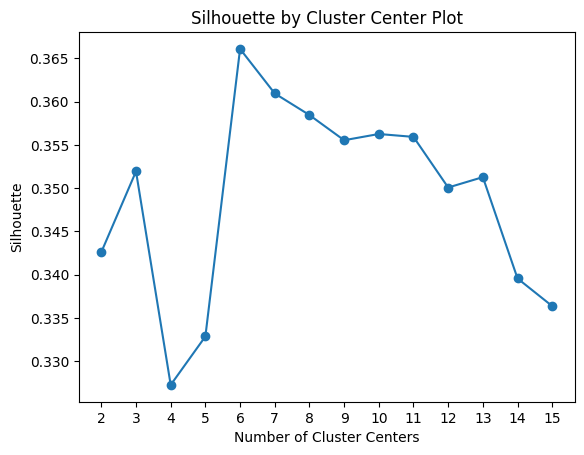
Our best silhouette score is 0.36 - not very promissing - with 6 clusters. Let's see what results the elbow technique yields.
def elbow_method_analysis(data, min_k=2, max_k=15, step=1):
range_num_clust = range(min_k, max_k+1, step)
sum_of_squared_distances = []
for k in range_num_clust:
# initialise kmeans
kmeans = KMeans(n_clusters=k)
kmeans.fit(data)
# adding inertia
sum_of_squared_distances.append(kmeans.inertia_)
f, ax = plt.subplots(1, 1)
ax.plot(range_num_clust, sum_of_squared_distances, marker='o')
ax.set_xlabel('Number of Cluster Centers')
ax.set_xticks(range_num_clust)
ax.set_xticklabels(range_num_clust)
ax.set_ylabel('Squared Distances')
ax.set_title('Squared Distances by Number of Cluster Centers Plot')
elbow_method_analysis(tsne_features_leg, max_k=15)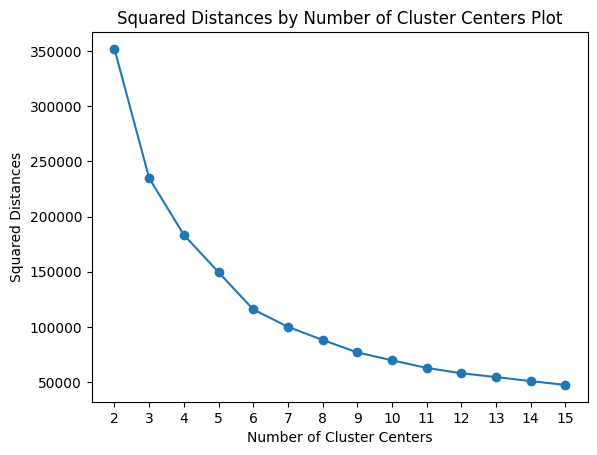
The results seem to point out to 6 as our best shot towards the ideal number of clusters. Let's use it.
alert_me()NUM_CLUSTERS = 6def cluster_data(data, num_clusters):
# Apply k-means clustering to the data
# Instantiate a KMeans object with 6 clusters
kmeans = KMeans(n_clusters=num_clusters, random_state=161803, n_init="auto")
# Fit the KMeans object to the data
kmeans.fit(data)
# Get the cluster labels
labels = kmeans.labels_
# Plot the data points in the new 2D space with the cluster labels
plt.scatter(data[:, 0], data[:, 1], c=labels, s=25, alpha=0.5)
# Annotate the centroids with cluster labels
for i, label in enumerate(set(labels)):
plt.annotate(label, (kmeans.cluster_centers_[i, 0], kmeans.cluster_centers_[i, 1]), color='r', fontsize=20, ha='center', va='center')
plt.xlabel('First Component')
plt.ylabel('Second Component')
plt.title('t-SNE transformed data with k-means clustering')
plt.legend()
plt.show()
return labels
labels_leg = cluster_data(tsne_features_leg, NUM_CLUSTERS)WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
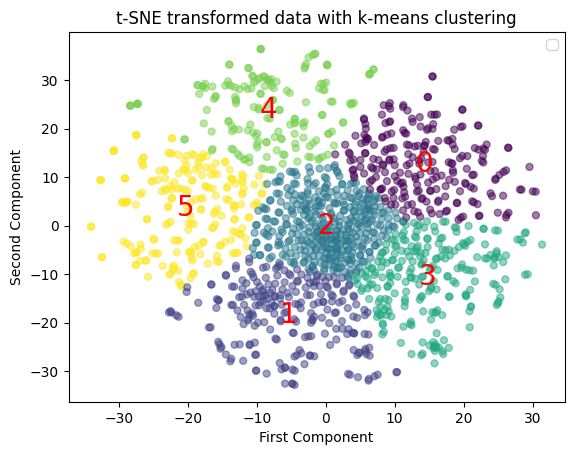
The results make it clear that there aren't well defined clusters of data. The boundaries of the clusters are actually quite close to what an evenly distributed (or regular radial gradient) would have, if divided into evenly equal parts: a hexagonal grid. Let's take a look in the counts of instances per cluster.
mapping_leg = {label:np.where(labels_leg == label)[0] for label in set(labels_leg)}
print('Label \t# inst\t% Total')
for k, v in mapping_leg.items():
print('{}\t{}\t{:.2f}'.format(k, len(v), len(v)/sum([len(item) for item in mapping_leg.values()])))Label # inst % Total
0 223 0.15
1 237 0.16
2 370 0.26
3 235 0.16
4 171 0.12
5 211 0.15
The counts confirm our initial analysis. Just to have some more confirmation about our conclusions, let's inspect the overall idea of the clusters individually. Let's try to visualize the main topics/words which are prevalent in each cluster.
We can use WordCloud to creade a visual representation of the most prevalent words in our document clusters. We are goint go use the TFIDF-filtered text we calculated previeously. We had the most common words (accross the whole dataset) removed from the text of each document. So now we need to emphasize the opposite: we stress the most common words inside each of the clusters, which is why we may use a CountVectorizer.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
clusters_leg = {k:[train_data_leg['tfidf_filtered_text'].iloc[idx] for idx in v] for k, v in mapping_leg.items()}
def create_word_cloud_images(clusters, use_count_vec=False, num_top_words=None, stopwords=None):
images_to_plot = []
image_captions = []
for cluster_label, list_of_documents in tqdm(clusters.items()):
if use_count_vec:
# Extract Keywords from Documents in the Cluster using CountVectorizer
vectorizer = CountVectorizer(max_features=num_top_words,
stop_words=stopwords)
counts = vectorizer.fit_transform(list_of_documents)
# Get feature names (words)
feature_names = vectorizer.get_feature_names_out()
# Calculate the term frequencies
term_frequencies = counts.sum(axis=0).A1
# SSelect Top N Keywords
top_n_keywords_indices = term_frequencies.argsort()[-num_top_words:][::-1]
top_n_keywords = [feature_names[idx] for idx in top_n_keywords_indices]
# Combine Top Keywords to Create 'cluster_text'
cluster_text = ' '.join(top_n_keywords)
else:
cluster_text = ' '.join(list_of_documents)
# Step 4: Generate Word Cloud
images_to_plot.append(WordCloud(width=400, height=400, background_color='white').generate(cluster_text))
caption = 'Cluster {} - {} documents - {}% of the total'.format(cluster_label,
len(list_of_documents),
"%.2f" % (len(list_of_documents)/sum([len(item) for item in clusters.values()])*100))
image_captions.append(caption)
return images_to_plot, image_captions
def show_images(images, captions):
# Create a grid of subplots
number_of_rows = (len(images) + 1) // 2
fig, axes = plt.subplots(nrows=number_of_rows, ncols=2, figsize=(15, 20))
# Iterate through the axes and plot the images
for ax, data, caption in zip(axes.flat, images, captions):
ax.imshow(data, interpolation='bilinear', cmap='viridis')
ax.set_title(caption, fontsize=10)
ax.axis('off')
# Adjust layout to prevent clipping of titles/labels
plt.tight_layout()
plt.subplots_adjust(hspace=0.1, wspace=0.05)
# Show the plot
plt.show()
def plot_clusters_into_word_clouds(clusters, use_count_vec=False, num_top_words=None, stopwords=None):
images, captions = create_word_cloud_images(clusters, use_count_vec, num_top_words, stopwords)
show_images(images, captions)plot_clusters_into_word_clouds(clusters_leg)100%|██████████| 6/6 [00:05<00:00, 1.04it/s]

Our primary result does'nt show much difference among the clusters. However, they are a bit cluttered. Let's try to keep only the most recurring words in each cluster.
plot_clusters_into_word_clouds(clusters_leg, use_count_vec=True, num_top_words=1000, stopwords=stopwords)100%|██████████| 6/6 [00:05<00:00, 1.02it/s]

The word-clouds in the images show a certain homogeneity among the themes of the documents, whose only variation is in the intensity in which the terms are recurrent. For isntance:
Let's try another way to visualize the themes in each cluster with NMF to extract their topics.
from sklearn.decomposition import NMF
def generate_topics_from_clusters(clusters, stopwords=None):
vectorizer = CountVectorizer(stop_words=stopwords)
for cluster_label, list_of_documents in clusters.items():
# Step 1: Vectorize the documents using CountVectorizer
count_matrix = vectorizer.fit_transform(list_of_documents)
# Step 2: Apply NMF
num_topics = 5 # Adjust the number of topics as needed
nmf_model = NMF(n_components=num_topics, random_state=161803)
nmf_model.fit(count_matrix)
# Step 3: Print the topics
feature_names = vectorizer.get_feature_names_out()
print("#######################################################")
print("# Topics in Cluster {} #".format(cluster_label))
print("#######################################################")
for topic_idx, topic in enumerate(nmf_model.components_):
top_words_indices = topic.argsort()[:-10 - 1:-1]
top_words = [feature_names[i] for i in top_words_indices]
print(f"Topic #{topic_idx + 1}: {', '.join(top_words)}")
print("-------------------------------------------------------\n\n")
generate_topics_from_clusters(clusters_leg, stopwords=stopwords)#######################################################
# Topics in Cluster 0 #
#######################################################
Topic #1: saúde, ações, estadual, igualdade, público, racial, ii, acesso, promoção, políticas
Topic #2: turismo, serviço, secretaria, nesta, desta, área, caso, qualquer, prazo, contrag
Topic #3: controle, ii, qualquer, iii, gac, atos, contrag, pesquisa, iv, proteção
Topic #4: serviço, rn, transporte, público, órgão, controle, pessoa, serviços, mediante, veículos
Topic #5: legislativa, ministério, público, artigo, ii, iii, graduação, pública, atividades, ensino
-------------------------------------------------------
#######################################################
# Topics in Cluster 1 #
#######################################################
Topic #1: social, assistência, rn, serviços, estadual, programas, ii, controle, governamentais, recursos
Topic #2: secretaria, cargo, estrutura, direitos, ii, ações, iii, agricultura, estadual, atos
Topic #3: estadual, empresas, complementar, desenvolvimento, ii, iii, desta, empresa, artigo, rn
Topic #4: horas, quadro, trabalho, iii, classe, administrativo, técnico, ii, nível, anexo
Topic #5: pública, segurança, defesa, social, rn, estadual, recursos, secretaria, órgãos, controle
-------------------------------------------------------
#######################################################
# Topics in Cluster 2 #
#######################################################
Topic #1: utilidade, pública, governadora, sede, foro, jurídico, associação, reconhece, neste, reconhecida
Topic #2: controle, atividades, geral, interno, ii, executivo, complementar, desta, nr, iii
Topic #3: gac, coordenadoria, atos, governador, controle, contrag, governamentais, doe, rn, bezerra
Topic #4: legislativa, assembleia, dezembro, orte, secretaria, artigo, disposições, revogadas, dá, outras
Topic #5: estadual, dia, governadora, sanciono, despachos, rn, oficial, fátima, bezerra, doe
-------------------------------------------------------
#######################################################
# Topics in Cluster 3 #
#######################################################
Topic #1: pública, utilidade, foro, sede, governadora, jurídico, legislativa, despachos, dá, neste
Topic #2: uso, sobre, produtos, pesquisa, base, saúde, direito, incentivo, informações, produção
Topic #3: decreto, ção, ão, ções, governador, prazo, artigo, dia, outras, revogadas
Topic #4: rn, doe, sanciono, governadora, gac, governador, bezerra, fátima, município, controle
Topic #5: estadual, rural, ii, jovens, complementar, meio, atividades, executivo, iv, realizar
-------------------------------------------------------
#######################################################
# Topics in Cluster 4 #
#######################################################
Topic #1: medida, meta, unidade, total, territorializaçãounidade, agenda, sistema, rn, central, gestão
Topic #2: recursos, fiscal, ordinários, encargos, despesas, programa, ano, base, pessoal, serviços
Topic #3: recursos, despesas, impostos, fiscal, transferências, fonte, órgão, programa, encargos, atendimento
Topic #4: ção, recursos, fiscal, ções, apoio, ência, programa, ão, secretaria, unidade
Topic #5: órgão, unidade, total, secretaria, medida, meta, quantidade, programa, rn, desenvolvimento
-------------------------------------------------------
#######################################################
# Topics in Cluster 5 #
#######################################################
Topic #1: total, medida, meta, territorializaçãounidade, unidade, programas, ano, base, demonstrativo, temáticos
Topic #2: horas, quadro, legislativa, cargos, cargo, públicos, secretaria, orte, assembleia, valores
Topic #3: superior, cargo, nível, área, atividades, atribuições, cargos, curso, código, judiciário
Topic #4: tribunal, atos, controle, ii, direito, justiça, iii, público, legislativa, contas
Topic #5: nível, classe, ii, cargos, provimento, efetivo, estadual, cargo, nr, complementar
-------------------------------------------------------
At first, while visualizing, we wondered if these findings were a real consequence of the dataset itself of some problem with the approach we used.
In order to ensure it was not a problem with our approach, we decided to use a different dataset, with mode clearly defined thematic differences, keeping the same approach, so that we may rule out the possibility of a possible problem in the development of the analysis.
As mentioned in the Introduction, this second dataset consists of
textual data from some specific thematic categories. So different from
the first dataset, there is some information about its domains, which
are labeled as alcorao, arduino,
cervantes, cristianismo,
culinaria, nheengatu, psicologia
and python. Additionally, there is information about the
book from which the document was originally taken (e.g.,
alcorao_1.pdf, nheengatu_1.pdf).
These additional fields for each document allow us to analyze the results, assessing the consistency of the clusters based in the distribution of the categories in each cluster.
from google.colab import drive
drive.mount('/content/drive')
DATA_URL = '/content/drive/MyDrive/Mestrado/PLN/corpus.pkl'Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
After loading, we format the data and prepare it to de used as a DataFrame, including the cleaning of the text.
with open(DATA_URL, 'rb') as afile:
rawdata = pickle.load(afile)
rawdata = dict(rawdata)
data = []
for domain, list_of_documents in rawdata.items():
if domain not in ['arduino','python']:
for doc in list_of_documents:
data.append([doc['text'], domain, doc['orig_book']])for doc in tqdm(data):
doc.append(remove_nonalph_characters(clean_breaks_and_periods(doc[0].lower())))
dataset = pd.DataFrame(data, columns=['raw_text', 'domain', 'orig_book', 'text'])100%|██████████| 2090/2090 [00:06<00:00, 347.24it/s]
dataset.head()| raw_text | domain | orig_book | text | |
|---|---|---|---|---|
| 0 | SciELO Books / SciELO Livros / SciELO Libros ... | psicologia | psicologia_1.pdf | scielo books scielo livros scielo libros zili... |
| 1 | A NATUREZA ComPoRTAmENTAL DA mENTE 15\nmicrôm... | psicologia | psicologia_1.pdf | a natureza comportamental da mente micrômegas... |
| 2 | 18 DIEgo ZILIo\nnortearam a construção da teo... | psicologia | psicologia_1.pdf | diego zilio nortearam a construção da teoria ... |
| 3 | primeirA p Arte\nFilosoFiA dA mente \ne behA ... | psicologia | psicologia_1.pdf | primeira p arte filosofia da mente e beha vio... |
| 4 | 26 DIEgo ZILIo\nbilidade da mente, já que “nã... | psicologia | psicologia_1.pdf | diego zilio bilidade da mente já que não pode... |
Now, we create the TFIDF representation of the data to be used in the visualization phases. We also split the data, as previously done, and prepare the text to create the Doc2Vec model.
dataset['high_ranked_words'], dataset['tfidf_filtered_text'] = create_tfidf_representation(dataset['text'])2090it [00:18, 113.28it/s]
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(dataset, test_size=0.2, random_state=161803)def gensim_preprocess(series, tokens_only=False):
for i, line in tqdm(enumerate(series)):
tokens = gensim.utils.simple_preprocess(line)
if tokens_only:
yield tokens
else:
# For training data, add tags
yield gensim.models.doc2vec.TaggedDocument(tokens, [i])
train = list(gensim_preprocess(train_data['text']))
test = list(gensim_preprocess(test_data['text'], tokens_only=True))1672it [00:02, 734.03it/s]
418it [00:00, 738.73it/s]
As a result of this process, we have 1672 instances to be used as train data, and 418 observations that compose the test set. The format of the representation of the data obtained is the same as we had with the previous dataset.
train[12]TaggedDocument(words=['porque', 'como', 'de', 'mim', 'testificaste', 'em', 'jerusalém', 'assim', 'importa', 'que', 'testifiques', 'também', 'em', 'roma', 'testemunho', 'pessoal', 'de', 'paulo', 'de', 'que', 'havia', 'visto', 'cristo', 'ressurreto', 'explícito', 'enfático', 'com', 'enumeração', 'de', 'lgumas', 'das', 'aparições', 'do', 'senhor', 'redivivo', 'ele', 'associa', 'seu', 'próprio', 'testemunho', 'ao', 'escrever', 'aos', 'santos', 'de', 'corinto', 'da', 'seguinte', 'forma', 'porque', 'primeiramente', 'vos', 'entreguei', 'que', 'também', 'recebi', 'que', 'cristo', 'morreu', 'por', 'nossos', 'pecados', 'segundo', 'as', 'escrituras', 'que', 'oi', 'sepultado', 'que', 'ressuscitou', 'ao', 'terceiro', 'dia', 'segundo', 'as', 'escrituras', 'que', 'foi', 'visto', 'por', 'cefas', 'depois', 'pelos', 'doze', 'depois', 'foi', 'visto', 'uma', 'vez', 'por', 'mais', 'de', 'quinhentos', 'irmãos', 'dos', 'quais', 'vive', 'ainda', 'maior', 'parte', 'mas', 'alguns', 'já', 'dormem', 'também', 'depois', 'foi', 'vi', 'sto', 'por', 'tiago', 'depois', 'por', 'todos', 'os', 'apóstolos', 'por', 'derradeiro', 'de', 'todos', 'me', 'apareceu', 'também', 'mim', 'como', 'um', 'abortivo', 'porque', 'eu', 'sou', 'menor', 'dos', 'apóstolos', 'que', 'não', 'sou', 'digno', 'de', 'ser', 'chamado', 'apóstolo', 'pois', 'que', 'persegui', 'igreja', 'de', 'deus', 'encerramento', 'do', 'ministério', 'apostólico', 'revelação', 'dada', 'joão', 'período', 'do', 'ministério', 'apostólico', 'continuou', 'até', 'perto', 'do', 'final', 'do', 'primeiro', 'século', 'de', 'nossa', 'era', 'aproximadamente', 'sessenta', 'setenta', 'anos', 'desde', 'tempo', 'da', 'ascensão', 'do', 'senhor', 'no', 'decurso', 'daquele', 'tempo', 'igreja', 'experimentou', 'tanto', 'prosperidade', 'quanto', 'vicissitude', 'inicialmente', 'corpo', 'organizado', 'cresceu', 'em', 'número', 'de', 'membros', 'influência', 'de', 'uma', 'forma', 'considerada', 'fenomenal', 'se', 'não', 'miraculosa', 'os', 'apóstolos', 'os', 'muitos', 'outros', 'ministros', 'que', 'trabalhavam', 'sob', 'direção', 'deles', 'em', 'posições', 'escalonadas', 'de', 'autoridade', 'esforçaram', 'se', 'tão', 'eficazment', 'em', 'espalhar', 'palavra', 'de', 'deus', 'que', 'paulo', 'escrevendo', 'aproximadamente', 'trinta', 'anos', 'depois', 'da', 'ascensão', 'afirmou', 'que', 'evangelho', 'já', 'havia', 'sido', 'levado', 'todas', 'as', 'nações', 'ou', 'para', 'usar', 'suas', 'próprias', 'palavras', 'pregado', 'toda', 'criatura', 'que', 'há', 'debaixo', 'do', 'céu', 'pela', 'ação', 'do', 'espírito', 'santo', 'cristo', 'continuava', 'dirigir', 'os', 'negócios', 'de', 'sua', 'igreja', 'na', 'terra', 'seus', 'representantes', 'mortais', 'os', 'apóstolos', 'viajavam', 'ensinavam', 'curava', 'os', 'aflitos', 'repreendiam', 'os', 'maus', 'espíritos', 'levantavam', 'os', 'mortos', 'para', 'uma', 'vida', 'renovada', 'falta', 'nos', 'relato', 'de', 'qualquer', 'aparição', 'pessoal', 'de', 'cristo', 'aos', 'mortais', 'entr', 'as', 'manifestações', 'paulo', 'revelação', 'joão', 'na', 'ilha', 'de', 'patmos', 'tradição', 'confirma', 'hipótese', 'de', 'que', 'joão', 'fora', 'para', 'lá', 'banido', 'por', 'causa', 'da', 'palavra', 'de', 'deus', 'pelo', 'testemunho', 'de', 'jesus', 'cristo', 'ele', 'afiança', 'que', 'que', 'escreveu', 'agora', 'conhecido', 'como', 'livro', 'de', 'apocalipse', 'revelação', 'de', 'jesus', 'cristo', 'qual', 'deus', 'lhe', 'deu', 'para', 'mostrar', 'aos', 'seus', 'servos', 'as', 'coisas', 'que', 'brevemente', 'devem', 'acontecer', 'pelo', 'seu', 'anjo', 'as', 'enviou', 'as', 'notificou', 'joão', 'seu', 'servo', 'apóstolo', 'dá', 'uma', 'vívida', 'descrição', 'do', 'cristo', 'glorificado', 'conforme', 'viu', 'as', 'palavras', 'do', 'senhor', 'ele', 'registrou', 'da', 'seguinte', 'maneira', 'não', 'temas', 'eu', 'sou', 'primeiro', 'último', 'que', 'vivo', 'fui', 'morto', 'mas', 'eis', 'aqui', 'estou', 'vivo', 'para', 'todo', 'sempre', 'amém', 'tenho', 'as', 'chaves', 'da', 'morte', 'do', 'inferno', 'joão', 'recebeu', 'ordem', 'de', 'escrever', 'cada', 'uma', 'das', 'sete', 'igrejas', 'ou', 'ramos', 'da', 'igreja', 'de', 'cristo', 'então', 'em', 'existência', 'na', 'ásia', 'administrando', 'repreensão', 'admoestação', 'encorajamento', 'conforme', 'condição', 'que', 'cada', 'uma', 'requeria', 'ministério', 'final', 'de', 'joão', 'marco', 'encerramento', 'da', 'administração', 'apostólica', 'na', 'igreja', 'primitiva', 'seus', 'companheiros', 'de', 'apostolado', 'haviam', 'ido', 'para', 'seu', 'repouso', 'maioria', 'deles', 'tendo', 'entrado', 'através', 'das', 'portas', 'do', 'martírio', 'embora', 'fosse', 'seu', 'privilégio', 'especial', 'permanecer', 'na', 'carne', 'até', 'ad', 'vento', 'do', 'senhor', 'em', 'glória', 'ele', 'não', 'deveria', 'continuar', 'seu', 'serviço', 'como', 'ministro', 'reconhecido', 'aceito', 'pela', 'igreja', 'dela', 'conhecido', 'mesmo', 'enquanto', 'os', 'apóstolos', 'viviam', 'trabalhavam', 'semente', 'da', 'apostasia', 'havia', 'lançado', 'raízes', 'na', 'igreja', 'havia', 'crescido', 'com', 'exuberância', 'das', 'ervas', 'daninhas', 'essa', 'condição', 'havia', 'sido', 'predita', 'tanto', 'pelos', 'profetas', 'do', 'velho', 'testamento', 'quanto', 'pelo', 'senhor', 'jesus', 'os', 'apóstolos', 'também', 'falaram', 'em', 'predição', 'clara', 'do', 'crescimento', 'da', 'apostasia', 'que', 'lhes', 'surgia', 'tão', 'afliti', 'vamente', 'diante', 'dos', 'olhos', 'como', 'movimento', 'em', 'franco', 'progresso', 'as', 'manifestações', 'pessoais', 'do', 'senhor', 'jesus', 'aos', 'mortais', 'parece', 'haverem', 'cessado', 'com', 'passamento', 'dos', 'apóst', 'olos', 'antigos', 'não', 'mais', 'foram', 'testemunhadas', 'até', 'amanhecer', 'da', 'dispensação', 'da', 'plenitude', 'dos', 'tempos', 'notas', 'do', 'capítulo', 'autoridade', 'presidente', 'consetimento', 'geral', 'outro', 'caso', 'de', 'ação', 'oficial', 'na', 'escolha', 'designação', 'de', 'homens', 'para', 'um', 'cargo', 'especial', 'na', 'igreja', 'levantou', 'se', 'pouco', 'depois', 'da', 'ordenação', 'de', 'matias', 'verifica', 'se', 'que', 'um', 'aspecto', 'marcante', 'da', 'organização', 'da', 'igreja', 'nos', 'primeiros', 'dias', 'dos', 'apóstolos', 'era', 'posse', 'comum', 'das', 'coisas', 'materiais', 'sendo', 'distribuição', 'feita', 'de', 'acordo', 'com', 'necessidade', 'como', 'cr', 'escesse', 'número', 'de', 'membros', 'achou', 'se', 'impraticável', 'que', 'os', 'apóstolos', 'devotassem', 'atenção', 'tempo', 'necessários', 'esses', 'assuntos', 'temporais', 'de', 'maneira', 'que', 'convocaram', 'os', 'membros', 'para', 'selecionarem', 'sete', 'homens', 'de', 'boa', 'reputação', 'aos', 'quais', 'pudessem', 'indicar', 'para', 'tomarem', 'encargo', 'especial', 'desses', 'problemas', 'tais', 'homens', 'foram', 'designados', 'por', 'oração', 'pela', 'imposição', 'das', 'mãos', 'caso', 'instrutivo', 'por', 'mostrar', 'que', 'os', 'apóstolos', 'tinham', 'consciência', 'de', 'possuírem', 'autoridade', 'para', 'dirigir', 'os', 'negócios', 'da', 'igreja', 'que', 'observavam', 'estritamente', 'princípio', 'do', 'consentimento', 'geral', 'na', 'administração', 'de', 'seu', 'alto', 'ofício', 'eles', 'exerciam', 'seus', 'poderes', 'sacerdotais', 'no', 'espírito', 'de', 'amor', 'com', 'devido', 'respeito', 'pelos', 'direitos', 'do', 'povo', 'qual', 'deviam', 'presidir', 'autor', 'grande', 'apostasia', 'pentecostes', 'palavra', 'significa', 'qüinquagésimo', 'aplicava', 'se', 'festa', 'judaica', 'que', 'se', 'celebrava', 'cinqüenta', 'dias', 'depois', 'do', 'segundo', 'dia', 'dos', 'pães', 'ázimos', 'ou', 'dia', 'da', 'páscoa', 'igualmente', 'conhecido', 'como', 'festa', 'das', 'semanas', 'êxo', 'deut', 'porque', 'de', 'acordo', 'com', 'estilo', 'hebreu', 'caía', 'sete', 'semanas', 'ou', 'uma', 'semana', 'de', 'semanas', 'depois', 'da', 'páscoa', 'chama', 'se', 'também', 'festa', 'da', 'colheita', 'êxo', 'dia', 'das', 'primicias', 'núm', 'pentecostes', 'era', 'uma', 'das', 'grandes', 'festas', 'de', 'israel', 'de', 'observação', 'obrigatór', 'ia', 'sacrifícios', 'especiais', 'eram', 'determinados', 'para', 'dia', 'como', 'também', 'uma', 'oferenda', 'adequada', 'estação', 'da', 'colheita', 'compreendendo', 'dois', 'pães', 'fermentados', 'feitos', 'com', 'trigo', 'novo', 'esses', 'deviam', 'ser', 'moídos', 'diante', 'do', 'altar', 'depois', 'dados', 'aos', 'sacerdotes', 'lev', 'em', 'virtude', 'dos', 'acontecimentos', 'sem', 'precedentes', 'que', 'caracterizaram', 'primeiro', 'pentecostes', 'após', 'ascensão', 'do', 'senhor', 'nome', 'tornou'], tags=[12])train_data['text'].iloc[12]{"type":"string"}Now we can create our Doc2Vec model.
model = gensim.models.doc2vec.Doc2Vec(vector_size=100, min_count=2, epochs=40)
model.build_vocab(train)
print(f"Word 'coração' appeared {model.wv.get_vecattr('coração', 'count')} times in the training corpus.")Word 'coração' appeared 416 times in the training corpus.
model.train(train, total_examples=model.corpus_count, epochs=model.epochs)Let's create a vector and see how close it is to the documents in the training set. Let's take advantage of our previous knowledge of the dataset and tailor our vector to be thematically close to one of Cervantes' works.
# Calculating the vector and its closest documents
model.random.seed(161803)
sample_vector = model.infer_vector([' a mais formosa donzela que diana viu em seus serros que vênus olhou em suas selvas. cruel vireno fugitivo eneias barrabás te carregue aos quintos do inferno. tu levas que impiedade nas garras de tuas mãos as entranhas de uma humilde tão apaixonada quanto terna. levaste três toucas de dormir e umas ligas de umas pernas que ao mármore de paros se igualam lisas brancas e negras. levaste dois mil suspiros que poderiam se de fogo fossem queimar duas mil troias se duas mil troias houvesse. cruel vireno fugitivo eneias barrabás te carregue aos quintos do inferno. de sancho teu escudeiro espero entranhas tão tenazes e tão duras que não livrem dulcineia do encantamento. da culpa que tu tens a triste carregue a pena que justos por pecadores às vezes pagam em minha terra. tuas mais belas aventuras em desventuras se transformem em sonhos teus prazeres tuas promessas em esquecimento. cruel vireno fugitivo eneias barrabás te carregue aos quintos do inferno. sejas tido por falso de sevilha a marchena de granada até loja de londres à inglaterra. se jogares pife ou bisca ou buraco os reis fujam de ti nem ases nem setes vejas. se cortares os calos sangue tuas feridas vertam e fiquem as raízes se arrancares os dentes. cruel vireno fugitivo eneias barrabás te carregue aos quintos do inferno. a enquanto assim se queixava a maltratada altisidora dom quixote cou olhando a. depois sem responder uma palavra virou o rosto para sancho e disse pela salvação de teus antepassados meu caro sancho te imploro que me digas a verdade por acaso levas as três toucas e as ligas de que fala esta donzela apaixonada ao que sancho respondeu as três toucas sim levo mas as ligas nem em sonhos. a duquesa cou admirada com a desfaçatez de altisidora porque mesmo considerando a atrevida engraçada e travessa não achava que pudesse chegar a tamanha desenvoltura; e como não tinha sido avisada dessa brincadeira cou mais surpresa ainda. o duque quis reforçar a graça de tudo e disse não me parece bem senhor cavaleiro que havendo recebido neste meu castelo o bom acolhimento que vos foi dispensado tenhais tido a audácia de levar pelo menos três toucas se é que não levastes as ligas de minha aia são indícios de um mau coração e mostras de um comportamento que não corresponde a vossa fama. devolvei as ligas a ela; se não eu vos desa o a uma batalha mortal sem receio de que magos canalhas me transformem ou mudem meu rosto como zeram com tosilos meu lacaio que travou combate convosco. não queira deus que eu desembainhe minha espada contra vossa ilustríssima pessoa de quem tantas mercês recebi respondeu dom quixote. devolverei as toucas porque diz sancho que as tem; quanto às ligas é impossível porque nem eu as recebi nem ele tampouco; e se esta vossa aia quiser olhar seus esconderijos com certeza as achará. eu senhor duque jamais fui ladrão nem o penso ser em toda a minha vida com a graça de deus. esta aia como ela mesma diz fala como uma apaixonada coisa de que não tenho culpa de modo que não tenho de pedir perdão nem a ela nem a vossa excelência a quem suplico me tenha em melhor opinião e me dê de novo licença para seguir meu caminho. caminho espero que deus torne tão bom senhor dom quixote disse a duquesa que sempre ouçamos boas novas de vossas façanhas. e andai com deus pois quanto mais vos detendes mais aumentais o fogo no peito das donzelas que vos olham; quanto à minha vou castigá la de modo que daqui por diante não se passe nem com a vista nem com as palavras. só mais uma quero que me escutes valoroso dom quixote disse então altisidora. peço te perdão pelo furto das ligas porque por deus e por minha alma eu as estou usando. caí no mesmo descuido daquele pastor de burros que esqueceu de contar o que montava. eu não disse disse sancho. ora se eu tenho cara de encobrir furtos se eu fosse mão leve meu governo teria me servido como uma luva dom quixote abaixou a cabeça numa reverência aos duques e a todos os presentes e virando as rédeas de rocinante seguido de sancho no burro saiu do castelo e tomou o caminho para zaragoza. a escucha mal caballero detén un poco las riendas no fatigues las ijadas de tu mal regida bestia. mira falso que no huyes de alguna serpiente era sino de una corderilla que está muy lejos de oveja. tú has burlado monstruo horrendo la más hermosa doncella que dïana vio en sus montes que venus miró en sus selvas. cruel vireno fugitivo eneas barrabás te acompañe allá te avengas. tú llevas llevar impío en las garras de tus cerras las entrañas de una humilde como enamorada tierna. llévaste tres tocadores y unas ligas de unas piernas que al mármol paro se igualan en lisas blancas y negras. llévaste dos mil suspiros que a ser de fuego pudieran abrasar a dos mil troyas si dos mil troyas hubiera. cruel vireno fugitivo eneas barrabás te acompañe allá te avengas. de ese sancho tu escudero las entrañas sean tan tercas y tan duras que no salga de su encanto dulcinea. de la culpa que tú tienes lleve la triste la pena que justos por pecadores tal vez pagan en mi tierra. tus más finas aventuras en desventuras se vuelvan en sueños tus pasatiempos en olvidos tus rmezas. cruel vireno fugitivo eneas barrabás te acompañe allá te avengas. seas tenido por falso desde sevilla a marchena desde granada hasta loja de londres a ingalaterra. si jugares al reinado los cientos o la primera los reyes huyan de ti ases ni sietes no veas. si te cortares los callos sangre las heridas viertan y quédente los raigones si te sacares las muelas. cruel vireno fugitivo eneas barrabás te acompañe allá te avengas.'])
similar_documents = model.dv.most_similar(sample_vector, topn=len(model.dv))
similar_documents = sorted(similar_documents, key=lambda x: x[1], reverse=True)
# Recalling the info about the closest document
idx_doc_most_similar = similar_documents[0][0]
print('MOST SIMILAR DOCUMENT {}\nDomain: {}\nOriginal Book: {}\nText:\n'.format(
similar_documents[0],
train_data['domain'].iloc[idx_doc_most_similar],
train_data['orig_book'].iloc[idx_doc_most_similar]
))
train_data['text'].iloc[idx_doc_most_similar]MOST SIMILAR DOCUMENT (89, 0.3143421709537506)
Domain: alcorao
Original Book: alcorao_3.pdf
Text:
{"type":"string"}As expected, we had as a result one of documents which are excerpts from one of Cervantes' books in the dataset, even though the degree of similarity is only 0.3.
Let's repeat the comparison of infered vectors to the documents in the dataset, looking for the most similar documents to it.
ranks = []
second_ranks = []
more_than_ten_away=[]
for doc_id in tqdm(range(len(train))):
model.random.seed(161803) # to enforce repeatability
inferred_vector = model.infer_vector(train[doc_id].words)
sims = model.dv.most_similar([inferred_vector], topn=len(model.dv))
rank = [docid for docid, sim in sims].index(doc_id)
if rank > 10: more_than_ten_away.append((rank, doc_id))
ranks.append(rank)
second_ranks.append(sims[1])
more_than_ten_away.sort(key=lambda x: x[0])100%|██████████| 1672/1672 [03:32<00:00, 7.85it/s]
Again, the ideal result would show all of the elements in
rank as zeroes and all of the results in
second_ranks are the documents with the closest similarity
to wach document in the training data.
Let's check how the model did on this task.
import collections
counter = collections.Counter(ranks)
print('############### RANKS ###############\n{}\t{}\t{}'.format('categ', '# obsv', '% Total'))
keys = list(counter.keys())
keys.sort()
for k in keys:
v = counter[k]
print('{}\t{}\t{}'.format(k, v, "{:.2f}".format(v/sum(counter.values()) * 100)))############### RANKS ###############
categ # obsv % Total
0 1660 99.28
1 3 0.18
2 1 0.06
3 2 0.12
4 1 0.06
469 1 0.06
717 1 0.06
1124 1 0.06
1342 1 0.06
1446 1 0.06
In about 99.4% of the cases, the model correctly classified the closest document as itself. Let's inspect one of these documents a bit closer.
print('Text of the Document ({}):\n"{}"\n'.format(doc_id, ' '.join(train[doc_id].words)))
for label, index in [
('SAME DOCUMENT', 0),
('MOST SIMILAR', 1),
('SECOND MOST SIMILAR', 2)]:
print('{} {}:\nDomain: {}\nOriginal Book: {}\nText:\n{}\n'.format(
label,
sims[index],
train_data['domain'].iloc[sims[index][0]],
train_data['orig_book'].iloc[sims[index][0]],
train_data['text'].iloc[sims[index][0]]))Text of the Document (1671):
"de era primeira vez na vida que fazia tal tentati va pois em meio todas as ansiedades que tivera jamais havia experimentado orar em voz alta depois de me haver retirado para lugar que previamente escolhera tendo olhado ao redor encontrando me só ajoelhei me comecei oferecer deus os desejo de meu coração apenas iniciara imediatamente se apoderou de mim uma força que me dominou por completo tão assombrosa foi sua influência que se me travou língua de modo que eu não podia falar uma densa escuridão formou se ao meu redor pareceu me por um momento que eu estava condenado uma destruição súbita mas usando todas as forças para clamar deus que me livrasse do poder desse inimigo que me subjugara no momento exato em que estava prestes sucumbir ao desespero abandonar me destr uição não uma ruína imaginária mas ao poder de algum ser real do mundo invisível que possuía uma força tão assombrosa como eu jamais sentira em qualquer ser exatamente nesse momento de grande alarme vi um pilar de luz acima de minha cabeça mais br ilhante que sol que descia gradualmente sobre mim assim que apareceu senti me livre do inimigo que me sujeitava quando luz pousou sobre mim vi dois personagens cujo esplendor glória desafiam qualquer descrição pairando no ar acima de mim um eles falou me chamando me pelo nome disse apontando para outro este meu filho amado ouve meu objetivo ao dirigir me ao senhor era saber qual de todas as seitas estava certa fim de saber qual me unir portanto tão logo me controlei suf iciente para poder falar perguntei aos personagens que estavam na luz acima de mim qual de todas as seitas estava certa pois até aquele momento jamais me ocorrera que todas estivessem erradas qual me unir foi me respondido que não me unisse qualq uer delas pois estavam todas erradas personagem que se dirigia mim disse que todos os seus credos eram uma abominação sua vista que aqueles religiosos eram todos corruptos que eles se aproximam de mim com os lábios mas seu coração está longe de mim ensinam como doutrina os mandamentos de homens tendo aparência de religiosidade mas negam meu poder novamente me proibiu de unir me qualquer delas muitas outras coisas disse me as quais não posso no momento escrever quando tornei oltar mim estava deitado de costas olhando para céu quando luz se retirou eu estava sem forças mas tendo logo me recuperado em parte fui para casa ao apoiar me na lareira minha mãe perguntou me que se passava respondi não se preocupe tu do está bem eu estou bem então disse ela aprendi por mim mesmo que não verdadeiro parece que adversário sabia nos primeiros anos de minha vida que eu estava destinado ser um perturbador um importunador de seu reino enão por que os poderes das trevas se uniriam contra mim por que oposição perseguição que se levantaram contra mim quase em minha infância alguns dias após dessa visão encontrei me por acaso na companhia de um dos pregadores metodistas que er muito ativo no já mencionado alvoroço religioso conversando com ele sobre religião aproveitei oportunidade para relatar lhe visão que tivera fiquei muito surpreso com seu comportamento tratou meu relato não só levianamente mas com grande desp rezo dizendo que tudo aquilo era do diabo que não havia tais coisas como visões ou revelações nestes dias que todas essas coisas haviam cessado com os apóstolos que nunca mais existiriam logo descobri entretanto que minha narração da história havia provocado muito preconceito contra mim entre os religiosos tornando se motivo de grande perseguição qual continuou aumentar embora eu fosse um menino obscuro de apenas quatorze para quinze anos de idade minha situação na vida fizesse de mim menino sem importância no mundo homens influentes preocupavam se bastante para incitar opinião pública contra mim provocar uma perseguição implacável isto se tornou ponto comum entre todas as seitas todas se uniram para perseguir me isso me levou refletir seriamente na época muitas vezes partir daí quão estranho era que um obscuro menino de pouco mais de quatorze anos de idade que estava também condenado necessidade de obter um sustento escasso com seu trabalho diário fosse con siderado suficientemente importante para atrair atenção dos grandes das seitas mais populares da época criando neles espírito da mais implacável perseguição injúria mas estranho ou não assim aconteceu isso foi com freqüência causa de grande risteza para mim contudo era um fato ter tido eu uma visão tenho pensado que me sentia como paulo quando apresentou sua defesa perante rei agripa relatou visão que tivera quando viu uma luz ouviu uma voz mas poucos foram também os que acredit aram nele alguns disseram que ele era desonesto outros que estava louco foi ridicularizado injuriado tudo isso porém não destruiu realidade da visão ele tivera uma visão sabia que tivera toda perseguição debaixo do céu não poderia fazer com que fosse de outra forma ainda que perseguissem até morte ele sabia saberia até último alento que tinha visto uma luz ouvido uma voz falando lhe mundo inteiro não poderia fazê lo pensar ou crer de outra maneira assim era comigo tinha realmente visto uma luz no meio dessa luz dois personagens eles realmente falaram comigo embora eu fosse odiado perseguido por dizer que tivera uma visão isso era verdade enquanto me perseguiam injuriando me afirmando falsamente to da espécie de maldades contra mim por dizê lo fui levado pensar em meu coração por que perseguir me por contar verdade tive realmente uma visão quem sou eu para opor me deus ou por que pensa mundo fazer me negar que realmente vi porque eu tivera uma visão eu sabia sabia que deus sabia não podia negá la nem ousaria fazê lo pelo menos eu tinha consciência de que se fizesse ofenderia deus estaria sob condenação"
SAME DOCUMENT (1671, 0.9911710619926453):
Domain: cristianismo
Original Book: cristianismo_1.pdf
Text:
de . era a primeira vez na vida que fazia tal tentati va pois em meio a todas as ansiedades que tivera jamais havia experimentado orar em voz alta. depois de me haver retirado para o lugar que previamente escolhera tendo olhado ao redor e encontrando me só ajoelhei me e comecei a oferecer a deus os desejo s de meu coração. apenas iniciara imediatamente se apoderou de mim uma força que me dominou por completo; e tão assombrosa foi sua influência que se me travou a língua de modo que eu não podia falar. uma densa escuridão formou se ao meu redor e pareceu me por um momento que eu estava condenado a uma destruição súbita. mas usando todas as forças para clamar a deus que me livrasse do poder desse inimigo que me subjugara no momento exato em que estava prestes a sucumbir ao desespero e abandonar me à destr uição não a uma ruína imaginária mas ao poder de algum ser real do mundo invisível que possuía uma força tão assombrosa como eu jamais sentira em qualquer ser exatamente nesse momento de grande alarme vi um pilar de luz acima de minha cabeça mais br ilhante que o sol que descia gradualmente sobre mim. assim que apareceu senti me livre do inimigo que me sujeitava. quando a luz pousou sobre mim vi dois personagens cujo esplendor e glória desafiam qualquer descrição pairando no ar acima de mim. um d eles falou me chamando me pelo nome e disse apontando para o outro este é meu filho amado. ouve o meu objetivo ao dirigir me ao senhor era saber qual de todas as seitas estava certa a fim de saber a qual me unir. portanto tão logo me controlei o suf iciente para poder falar perguntei aos personagens que estavam na luz acima de mim qual de todas as seitas estava certa pois até aquele momento jamais me ocorrera que todas estivessem erradas e a qual me unir. foi me respondido que não me unisse a qualq uer delas pois estavam todas erradas; e o personagem que se dirigia a mim disse que todos os seus credos eram uma abominação a sua vista; que aqueles religiosos eram todos corruptos; que eles se aproximam de mim com os lábios mas seu coração está longe de mim; ensinam como doutrina os mandamentos de homens tendo aparência de religiosidade mas negam o meu poder . novamente me proibiu de unir me a qualquer delas; e muitas outras coisas disse me as quais não posso no momento escrever. quando tornei a v oltar a mim estava deitado de costas olhando para o céu. quando a luz se retirou eu estava sem forças; mas tendo logo me recuperado em parte fui para casa. ao apoiar me na lareira minha mãe perguntou me o que se passava. respondi não se preocupe tu do está bem eu estou bem . então disse a ela aprendi por mim mesmo que o presbiterianismo não é verdadeiro . parece que o adversário sabia nos primeiros anos de minha vida que eu estava destinado a ser um perturbador e um importunador de seu reino; s enão por que os poderes das trevas se uniriam contra mim por que a oposição e a perseguição que se levantaram contra mim quase em minha infância alguns dias após dessa visão encontrei me por acaso na companhia de um dos pregadores metodistas que er a muito ativo no já mencionado alvoroço religioso; e conversando com ele sobre religião aproveitei a oportunidade para relatar lhe a visão que tivera. fiquei muito surpreso com seu comportamento; tratou meu relato não só levianamente mas com grande desp rezo dizendo que tudo aquilo era do diabo que não havia tais coisas como visões ou revelações nestes dias; que todas essas coisas haviam cessado com os apóstolos e que nunca mais existiriam. logo descobri entretanto que minha narração da história havia provocado muito preconceito contra mim entre os religiosos tornando se motivo de grande perseguição a qual continuou a aumentar; e embora eu fosse um menino obscuro de apenas quatorze para quinze anos de idade e minha situação na vida fizesse de mim u m menino sem importância no mundo homens influentes preocupavam se o bastante para incitar a opinião pública contra mim e provocar uma perseguição implacável. e isto se tornou ponto comum entre todas as seitas todas se uniram para perseguir me. isso me levou a refletir seriamente na época e muitas vezes a partir daí; quão estranho era que um obscuro menino de pouco mais de quatorze anos de idade que estava também condenado à necessidade de obter um sustento escasso com seu trabalho diário fosse con siderado suficientemente importante para atrair a atenção dos grandes das seitas mais populares da época criando neles o espírito da mais implacável perseguição e injúria mas estranho ou não assim aconteceu e isso foi com freqüência causa de grande t risteza para mim. contudo era um fato ter tido eu uma visão. tenho pensado que me sentia como paulo quando apresentou sua defesa perante o rei agripa e relatou a visão que tivera quando viu uma luz e ouviu uma voz; mas poucos foram também os que acredit aram nele; alguns disseram que ele era desonesto outros que estava louco; e foi ridicularizado e injuriado. tudo isso porém não destruiu a realidade da visão. ele tivera uma visão sabia que a tivera e toda a perseguição debaixo do céu não poderia fazer com que fosse de outra forma; e ainda que o perseguissem até a morte ele sabia e saberia até o último alento que tinha visto uma luz e ouvido uma voz falando lhe; e o mundo inteiro não poderia fazê lo pensar ou crer de outra maneira. assim era comigo. tinha realmente visto uma luz e no meio dessa luz dois personagens; e eles realmente falaram comigo; e embora eu fosse odiado e perseguido por dizer que tivera uma visão isso era verdade; e enquanto me perseguiam injuriando me e afirmando falsamente to da espécie de maldades contra mim por dizê lo fui levado a pensar em meu coração por que perseguir me por contar a verdade tive realmente uma visão; e quem sou eu para opor me a deus ou por que pensa o mundo fazer me negar o que realmente vi porque eu tivera uma visão; eu sabia o e sabia que deus o sabia e não podia negá la nem ousaria fazê lo; pelo menos eu tinha consciência de que se o fizesse ofenderia a deus e estaria sob condenação.
MOST SIMILAR (1440, 0.6239825487136841):
Domain: cristianismo
Original Book: cristianismo_1.pdf
Text:
digo vos que de toda palavra ociosa que os homens disserem hão de dar conta no dia do juízo. buscadores de sinais a lição do mestre embora reforçada por exemplos e analogias por aplicações diretas e por franca declaração de autoridade caiu em ouvidos praticamente surdos à verdade espiritual e não enc ontrou lugar no coração já empedernido por grande estoque de maldade. responderam à profunda sabedoria e valiosas instruções da palavra de deus com um pedido impertinente mestre quiséramos ver de tua parte algum sinal. não tinham já visto sinais em pro fusão não tinham os cegos e os surdos os mudos e os enfermos os paralíticos e os hidrópicos e pessoas atacadas de toda sorte de doenças sido curados em suas casas em suas ruas e nas suas sinagogas demônios não tinham sido expulsos e suas abominávei s vozes silenciadas pela palavra dele e não tinham os mortos voltado à vida e tudo isso por meio dele a quem agora importunavam em busca de um sinal desejavam algum prodígio extraordinário para satisfazer sua curiosidade ou talvez para proporcionar lhes outras desculpas para agirem contra ele queriam sinais para desperdiçar em sua concupiscência. não é de admirar que cristo tenha suspirado profundamente em s eu espírito quando tais exigências lhe foram feitas. e replicou aos escribas e fariseus que haviam demonstrado tal desatenção às suas palavras uma geração má e adúltera pede um sinal; mas nenhum sinal lhe será dado senão o do profeta jonas. o sinal de jonas significava que por três dias estivera no ventre do peixe sendo depois restituído à liberdade. assim também o filho do homem seria encerrado na sepultura e depois se levantaria novamente. esse era o único sinal que ele lhes daria e pelo mesmo seriam condenados. contra eles e sua geração os homens de nínive erguer se iam em julgamento pois estes iníquos que eram haviam se arrependido pela pregação de jonas; e agora um maior que jonas estava entre eles. a rainha de sabá levant ar se ia em julgamento contra eles pois viera dos confins da terra para auferir a sabedoria de salomão; e agora um maior que salomão se encontrava entre eles. depo is retornando ao assunto dos espíritos iníquos e imundos sobre o qual haviam espalhado a acusação de que estava ligado a satanás disse lhes que quando um demônio é expulso tenta após um período de solidão retornar à casa ou corpo do qual foi expelid o; mas encontrando essa casa em ordem agradável e limpa depois que seu imundo ser se viu forçado a vagá la convoca outros espíritos piores do que ele mesmo que tomam conta do homem levando o a um estado ainda pior do que o anterior. neste estranho exemplo está simbolizada a condição daqueles que depois de terem recebido a verdade ficando livres das impuras influências do erro e do pecado tornando se em ment e espírito e corpo como uma casa varrida e adornada em imaculada ordem renunciam mais tarde ao bem abrem sua alma aos demônios da falsidade e do engodo e tornam se mais corruptos que antes. assim declarou o senhor acontecerá também a esta geração má. embora os escribas e fariseus não estivessem convencidos e talvez nem mesmo impressionados com seus ensinamentos nosso senhor não se encontrava completamente destituído de ouvintes apreciativos. uma mulher do grupo elevou sua voz invocando bênção para a mãe que havia tido aquele filho e para os seios que o haviam amamentado. sem rejeitar esse tributo de reverência que se aplicava tanto à mãe quanto ao filho jesus respondeu antes bemaventurados são os que ouvem a palavra de deus e a guardam cristo é procurado por sua mãe e seus irmãos enquanto jesus estava ocupado com os escribas e fariseus e um grande número de outras pessoas possivelmente por volta do momento em que concluía as palavras que acabamos de considerar avisaram lhe que sua mãe e seus irmãos estavam presentes e desejavam falar lhe. em conseqüência do aglomerado de pessoas ao seu redor não conseguiram chegar até ele. usando a circunstância para demonstrar a todos o fato de que seu trabalho tinha precedência sobre as reivindicações familiares e assim explicando que não podia reunir se a seus parentes no momento perguntou quem é minha mãe e quem são meus irmãos respondendo à sua própria pergunta e expressando nessa resposta o pensamento mais profundo que existia em sua mente disse apontando para os discípulos eis aqui minha mãe e meus irmãos; porque qualquer que fizer a vontade de meu pai que está nos céus este é meu irmão e irmã e mãe. o incidente nos recorda a resposta que dera a sua mãe quando juntamente com josé o tinham encontrado no templo após uma longa e ansiosa busca por que é que me procuráveis não sabíeis que me convém tratar dos negócios de meu pai desses mesmos negócios se ocupava ele quando sua mãe e seus irmãos desejaram falar lhe encontrando se no meio da multidão. os direitos superiores da obra de seu pai faziam no adiar todos os assuntos de importância menor. não há justificativa para considerarmos essas observações como evidência de desrespeito e muito menos de deslealdade filial e familiar. uma devoção da mesma espécie esperava ele dos apóstolos que eram chamados a dedicar sem reservas tempo e talento ao ministério. não é revelado o propósito com que os familiares de jesus o procuraram. podemos deduzir portanto que o mesmo não tinha grande importância fora do círculo familar. notas do capí tulo . os dois relatos do milagre. em nosso comentário sobre a cura miraculosa do servo do centurião seguimos em grande parte o relato mais circunstancial de lucas. o registro de mateus sobre a petição do oficial mais breve apresenta o homem
SECOND MOST SIMILAR (1190, 0.6056472659111023):
Domain: cristianismo
Original Book: cristianismo_1.pdf
Text:
compreender a doutrina de cristo concernente a si próprio especialmente no tocante à sua relação com o pai jesus lhes disse porque eu desci do céu não para fazer a minha vontade mas a vontade daquele que me enviou. e depois continuando a lição baseada no contraste entre o maná que alimentara seus pais no deserto e o pão da vida que ele oferecia acrescentou eu sou o pão vivo que desceu do céu e novamente decla rou o pai que vive me enviou. não foram poucos os discípulos incapazes de compreender seus ensinamentos; e seus protestos provocaram estas palavras isto escandaliza vos que seria pois se vísseis subir o filho do homem para onde primeiro estava . a certos judeus iníquos envoltos no manto do orgulho racial e que se jactavam de sua descendência através da linhagem de abraão tentando desculpar seus próprios pecados com o uso injustificado do nome do grande patriarca nosso senhor assim proclamou sua própria preeminência em verdade em verdade vos digo que antes que abraão existisse eu sou. o significado mais amplo deste comentário será discutido adiante; é suficiente no momento que se considere esta escritura como uma franca admissão da precedência e supremacia do senhor sobre abraão. mas como o nascimento de abraão precedeu o de cristo por mais de dezenove séculos tal prioridade deve referir se a uma existência anterior ao estado mortal. ao se aproximar a hora da traição na sua última entrevista com os apóstolos antes da angustiante experiência em getsêmani jesu s confortou os dizendo pois o mesmo pai vos ama ; outra vez deixo o mundo e vou para o pai. ademais na oração por aqueles que haviam sido fiéis aos seus teste munhos da função messiânica de jesus ele dirigiu se ao pai com esta invocação solene e a vida eterna é esta que te conheçam a ti só por único deus verdadeiro e a jesus cristo a quem enviaste. eu glorifiquei te na terra tendo consumado a obra que m e deste a fazer. e agora glorifica me tu ó pai junto de ti mesmo com aquela glória que tinha contigo antes que o mundo existisse. as escrituras do livro de mórmo n são igualmente explícitas quanto às provas da preexistência de cristo e da pré designação de sua tarefa. somente uma das muitas evidências ali encontradas será citada aqui. um profeta antigo designado nos registros como o irmão de jarede certa vez demandou com o senhor em súplica especial e o senhor disse lhe crês nas palavras que eu direi e ele respondeu sim senhor eu sei que falas a verdade porque és u m deus de verdade e não podes mentir. e quando disse estas palavras eis que o senhor se mostrou a ele e disse por saberes estas coisas ficas redimido da queda; portanto és conduzido de volta a minha presença; portanto mostro me a ti. eis que eu sou aqu ele que foi preparado desde a fundação do mundo para redimir meu povo. eis que eu sou jesus cristo. eu sou o pai e o filho. em mim toda a humanidade terá vida e tê la á eternamente sim aqueles que crerem em meu nome; e eles tornar se ão meus filhos e min has filhas. e nunca me mostrei ao homem que criei porque nunca o homem creu em mim como tu creste. vês que foste criado segundo minha própria imagem sim todos os homens foram criados no princípio à minha própria imagem. eis que este corpo que ora vês é o corpo do meu espírito; e o homem foi por mim criado segundo o corpo do meu espírito; e assim como te apareço em espírito aparecerei a meu povo na carne. os fat os principais evidenciados por esta escritura e que têm relação direta com o assunto presente são as manifestações do cristo enquanto ainda no seu estado pré mortal e a sua declaração de que havia sido escolhido desde a fundação do mundo para ser o rede ntor. as revelações dadas através dos profetas de deus na atual dispensação estão repletas de evidências sobre a designação e ordenação de cristo no mundo primevo; e todo o conteúdo das escrituras encontradas em doutrina e convênios pode ser chamado em tes temunho. os seguintes exemplos ilustram particularmente este ponto. em maio de em uma comunicação a joseph smith o profeta o senhor declarou ser aquele que havia em outros tempos vindo do pai para o mundo e de quem joão havia prestado testemunho como sendo o verbo; e é reiterada a verdade solene de que ele jesus cristo era no princípio antes de o mundo existir e mais que ele era o redentor que veio ao mundo porque o mundo foi feito por ele e nele estava a vida dos homens e a luz dos home ns. novamente a escritura refere se a ele como unigênito do pai cheio de graça e verdade que veio e habitou na carne. na mesma revelação o senhor disse e agora na verdade vos digo eu estava no princípio com o pai e eu sou o primogênito. numa ocasião anterior como testifica o profeta moderno ele e seu companheiro de sacerdócio foram iluminados pelo espírito de maneira que se tornaram capazes de ver e compreender as coisas de deus até as coisas que existiram desde o princípio antes do mundo existir as quais foram ordenadas pelo pai por meio do seu filho unigênito que estava no seio do pai desde o princípio; de quem testemunhamos; e o testemunho q ue prestamos é a plenitude do evangelho de jesus cristo que é o filho o qual vimos e com quem conversamos na visão celestial. o testemunho das escrituras dadas a ambos os hemisférios tanto as antigas quanto as modernas; as inspiradas declarações dos profetas e apóstolos e as palavras do próprio mestre são unânimes em proclamar a preexistência de cristo e a sua ordenação para salvador e redentor da humanidade no começo sim mesmo antes da fundação do mundo. notas do capítulo . diferentes níveis das inteligências no estado pré mortal. uma revelação a abraão mostra com grande clareza que os espíritos dos homens existiram como inteligências individuais de vári os graus de habilidade e poder antes de estabelecido o estado mortal na terra e mesmo antes da criação do mundo como habitação adequada para os seres humanos ora o senhor mostrara a mim abraão as inteligências que foram organizadas antes de o mundo e xistir; e entre todas essas havia muitas nobres e grandes. e deus viu que essas almas eram boas; e ele estava no meio delas e disse a estes farei meus governantes; pois ele se encontrava entre aqueles que eram espíritos e
This particular document was a hit, both in being correctly classified as the closest to itself and also in having the second and third most similar documents addressing a related matter (regulation of familiar agriculture and sanitary insections in this context).
Now, let's take a look in random documents, taking a look in the
similar documents in the second_rank.
# Pick a random document from the corpus and infer a vector from the model
import random
doc_id = random.randint(0, len(train) - 1)
sim_id = second_ranks[doc_id]
print('Random Document in `train` ({}):\n"{}"\n'.format(doc_id, ' '.join(train[doc_id].words)))
print('Similar Document {}:\nDomain: {}\nOriginal Book: {}\nText:\n{}\n'.format(
sim_id,
train_data['domain'].iloc[sim_id[0]],
train_data['orig_book'].iloc[sim_id[0]],
train_data['text'].iloc[sim_id[0]]))Random Document in `train` (468):
"carnes qual significado carne muito magra requer gordura extra para que fique úmida no cozimento use gordura de porco que gela bem facilita seu manuseia lardear esta técnica usada para umedecer carne magra por dentro no cozimento medida que gordura derrete absorvida pela carne ficando mais suculenta para dar sabor extra tempere gordura ou ponha em marinada no mínimo hora bardear carne magra pode ser envolvida com toucinho para ficar úmida manter seu formato ele desaparece no cozimento mas se ficar algum deve ser retirado antes de servir exceto se for usado para decorar veja direita como preparar carne bovina vitelacarne bovina de vitela oferecem uma grande variedade de cortes desde filés magros macios fritos rapidamente aos cortes saborosos como músculo por exemplo que deve ser cozido lentamente preparo correto cuidadoso fundamental como preparar peças algumas peças como acém da foto tem uma camada grossa de gordura que deve ser retirada antes de cozinhar limpe gordura externa deixando uma camada fina para manter umidade como preparar contrafilés filés devem ser limpos temperados antes de cozinhar primeiro retire excesso de gordura deixando uma camada fina uniforme para dar sabor carne durante cozimento depois dê piques na gordura até carne com espaços regulares isso evita que filé enrole ao ser frito contrafilé ilustrado aqui filé de alcatra requer mesma técnica corte retire excesso de gordura com faca de desossar deixando cm próximo da carne faça cortes na gordura com espaços regulares com faca de cozinha ou dê piques com tesoura de cozinha como lardear bardear com toucinho alguns cortes de carne têm pouca gordura quando assados ou refogados necessário às vezes adicionar gordura para que fiquem macios suculentos isso pode ser feito recheando ou cobrindo com toucinho lardear com toucinho enfie uma agulha de lardear na carne no sentido do veio enfie na agulha uma tira debardear com toucinho envolva toda carne com uma camada fina de toucinho amarre com barbante verdecorar com toucinho envolva as laterais da carne com fatias de toucinho cubra com outra tira cortada em zi guezague prenda nas pontas como preparar carne bovina vitela como desossar peito de vitela pedaços grandes podem ser cozidos com ou sem osso pedaços desossados cozinham de modo mais uniforme são mais fáceis de fatiar depois de desossada carne está pronta para ser enrolada amarrada com ou sem recheio ou para ser fatiada contorne os ossos da costela com ponta da faca de desossar despregue os ossos da carne corte através da cartilagem em volta do osso do peito retire osso retire as costelas tire as cartilagens nervos ou excesso de gordura como enrolar rechear amarrar peças sem osso podem ser amarradas para assar ou refogar para manter toucinho no lugar ver ou segurar recheio recheio dá mais sabor ajuda umedecer carne de dentro para fora ajuda também fazer carne render mais passe barbante duas vezes no comprimento do rolo amarre mas não corte passe barbante em volta de uma das mãos enfie sua ponta formando um laço escorregue sobre carne puxe repita no rolo inteiro dê dois nós para arrematar coloque peito desossado na tábua com pele para baixo espalhe recheio uniformemente começando da ponta mais grossa enrole carne formando um cilindro bem feito maneira simples de amarrar em vez da técnica ensinada nos passos esquer da há uma série de nós para amarrar uma peça de filé para cozinhar por igual passe barbante em volta do filé no comprimento amarre bem corte as pontas amarre outro pedaço de barbante em volta da parte central do filé dê dois nós corte as pontas recomece com uma das extremidades trabalhe até centro do filé amarrando pedaços de barbante cada cm dando nó cortando medida que for trabalhando truque do chef carnes carpaccio de filé mignon peça inteira sal pimenta do reino moído na hora ml de azeite extravirgem suco de limão manjericão fresco picado algumas atcaparras lascas de parmesão enroladas ver quadro na limpe carne tirando excesso de gordura membrana ver direita enrole em papel alumínio congele corte em fatias bem finas veja direita arrume as fatias de carne em pratos individuais levemente sobrepostas cobrindo toda superfície um pouco antes de servir tempere ligeiramente as fatias com sal pimenta pingue azeite suco espalhe manjericão alcaparra parmesão rende porções truque do chef filés macios carne ser frita rapida mente fica mais macia se for batida isso ajuda quebrar os tecidos conjuntivos pode se usar rolo de macarrão em vez do cutelo da foto coloque bife na tábua bata bife usando lado achatado de um cutelo como limpar cortar filé mignon filé mignon melhor corte de carne bovina carne magra muito macia uma peça clássica para assar simples ou recheada coberta ou não com massa ver se cortada em fatias produzirá tournedos ou filés châuteaubriand um filé muito grosso retirado do centro da peça ou tiras para serem fritas em pouco óleo retire músculo da lateral da parte principal corte membrana do nervo enfiando lâmina da faca por baixo puxando membrana com outra mão corte filé em fatias de cerca de cm na extremidade mais fina corte os filés mais grossos depois bata os com parte chata de um cutelo ou um batedor decomo cortar filés bem finos congelar carne deixa suas fibras firmes facilita seu corte use esta técnica para carpaccio ver quadro esquerda ou para fritar em pouco óleo embrulhe em papel alumínio uma peça limpa de filé mignon congele por horas de pendendo do tamanho tire do congelador corte em fatias bem finas em movimentos de vaivém deixe descongelar como cortar carne para refogar para cozimento lento prolongado como ensopados refogados você pode usar cortes como acém mostrado aqui músculo ou aba de filé de carne bovina ou lombo peito de vitela durante cozimento músculo rijo amolece os tecidos gelatinosos se rompem derretem no molho fazendo com que ele fique saboroso aveludado para isso carne deve ser cortada em pedaços regulares seja em cubos seja em tiras para cozinhar por igual tire excesso de gordura nervos em volta da carne usando faca de desossar jogue fora gordura corte carne contra veio em fatias de cm com faca de cozinha vire os pedaços de lado corte os ao meio corte cada pedaço de carne em cubos de cm carne está pronta para ser ensopada ou refogada"
Similar Document (1257, 0.8294402956962585):
Domain: culinaria
Original Book: culinaria_7.pdf
Text:
como usar carne moída como dar formas diferentes ao modelar carne moída molhe as mãos com um pouco de água sem pressionar muito se moldar de forma compacta a textura da carne depois de frita ficará pesada e elástica. brochettes espetinhos pegue um pouco de carne moída tradicionalmente a de cordeiro e modele a em volta de espetinhos de metal apertando com os dedos.almôndegas enrole a carne moída na palma das mãos formando uma bola ou sobre uma superfície lisa. o tamanho varia de cm.como fazer bolo de carne para este prato americano use carne moída levemente gordurosa como paleta. a mistura de carne bovina vitela e porco é ideal quanto ao sabor e à umidade. adicione migalhas de pão embebidas no leite para absorver o suco da carne. forma livre umedeça as mãos com água para evitar que grude depois modele a carne na forma de pão retangular sobre a assadeira levemente untada.moldado pressione a carne num prato retangular levemente untado. alise a superfície com a colher depois vire o bolo em assadeira levemente untada. como fazer c r é p i n ett es estas delícias francesas são uma espécie de lingüiça caseira trata se de carne moída com migalhas de pão e temperos envolvida em uma membrana animal ver box a direita . tradicionalmente usa se lingüiça de porco mas pode se usar carne moída de cordeiro vitela ou aves. as crépinettes podem ser fritas grelhadas ou assadas no forno.misture a carne moída com cebola finamente picada migalhas de pão e temperos. faça pasteizinhos com as mãos e ponha um ramo de erva sobre cada um para decorar. embrulhe em qua drados feitos com a membra na colocada de molho e escorrida e frite em óleo e manteiga por minutos. como fazer steak tartare este prato feito com carne bovina finamente picada steak tartare é um dos grandes clássicos franceses. na frança é usual servi lo com cornichons pepinos novos em conserva alcaparras molho tabasco e com um pote de mostarda ao lado. usa se somente filé fresco e de primeira picado a mão um pouco antes de servir. limpe um filé de g por pessoa retirando toda a gordura membrana e nervos. pique a carne com duas facas ver p. . misture com cebola finamente picada e salsinha fresca sal e pimenta do reino. molde a carne em rodelas coloque as em pratos individuais faça uma cova no centro com a parte posterior de uma colher. ponha uma gema em cada cova. sirva imediatamente.peritonio é uma membrana fina com veios de gordura que envolve o estômago do animal; o peritônio de porco é o mais fácil de encontrar. em francês é chamado de crépine sendo usado para umedecer e dar sabor aos alimentos e manter os ingre dientes ligados no cozimento. dependendo da espessura o peritônio pode derreter na fritura ou permanecer neste caso deve ser retirado antes de servir. e possível consegui lo no açougue mas tem de ser encomendado. deixe de molho de i horas em água fria antes de usá lo. alcaparras molho tabasco e com um pote de mostarda ao lado. usa se somente filé fresco e de primeira picado a mão um pouco antes de servir. limpe um filé de g por pessoa retirando toda a gordura membrana e nervos. pique a carne com duas facas ver p. . misture com cebola finamente picada e salsinha fresca sal e pimenta do reino. molde a carne em rodelas coloque as em pratos individuais faça uma cova no centro com a parte posterior de uma colher. ponha uma gema em cada cova. sirva imediatamente. carnes invólucros ê recheios para lingüiça muitos açougues vendem invólucros para lingüiças. pode se usar tripa de boi e de porco como alternativa natural para invólucros prontos. para fazer lingüiça do tipo italiana misture carne com tomate seco alho e manjericão. use condimentos indianos como curry em pó coentro fresco picado e chutney de manga para dar umidade e fazer liga. para sabores mais tradicionais misture hortelã e cebola com carne de cordeiro sálvia e maçã com carne de porco e raiz forte ou mostarda com carne bovina. segurança em primeiro lugar miúdos devem ser manuseados cuidadosamente sendo impres cindível que estejam frescos. escolha carne úmida e brilhante sem nenhuma parte ressecada; evite miúdos com cor esverdeada superfície limosa ou cheiro forte. guarde os na geladeira e use no máximo dentro de dias. lave os muito bem antes de usar tipos de fígado fígado de novilho tem sabor suave e é muito macio. fica me lhor grelhado sautée ou frito. fígado de cordeiro tende a ser mais seco e não tão delicado quanto o de novilho mas também pode ser sautée. fígado de porco é forte e ideal para patês e terrinas. fígado de frango tem sabor suave e delicado; é usualmente frito e usado em patês.como fazer lingüiças a vantagem de fazer lingüiça em casa é que você sabe exatamente o que contém. carne de porco moída é a mais usada mas carne bovina de cordeiro e veado também são adequadas. o invólucro pode ser natural ou confeccionado e você pode variar sabores e temperos a gosto. deixe o invólucro de molho numa tigela grande com água fria por horas para retirar o excesso de sal e coloque a carne moída no saco de confeitar com bico grande. prenda o invó lucro no bico e esprema o o invólucro ficar mais flexível recheio para dentro. torça a lingüiça em espaços regulares e amarre os com barbante. retire o barbante depois do cozimento. miúdos miúdos são as partes internas e as extremidades de animais. desde os conhecidos fígado e rins até partes mais originais todos são nutritivos e preparados cuidadosamente tão saborosos como qualquer carne. como preparar fígado fígados de galinha são vendidos inteiros outros em geral já cortados mas podem ser encomendados inteiros. ao preparar o fígado inteiro divida os lóbulos e retire os canais ou tecidos conjuntivos. corte todos os veios sangüíneos sem danificar a carne. aqui é mostrado fígado de cordeiro. com os dedos retire a membrana opaca seguran do o fígado para evitar que a carne se rompa. corte o fígado em bifes de mm de espessura com a faca de cozinha. retire todos os dutos internos.o truque do chef deixando de molho o fígado de porco tem um sabor forte e pronunciado. deixe o de molho no leite para suavizá lo antes do cozimento. prepare o fígado ver ao lado . numa tigela coloque leite frio até cobrir o fígado e vire para envolvê lo. deixe de molho por cerca de i hora. tipos de fígadoinvólucros ê recheios para lingüiça o truque do chef
We can see that there is also a close similarity between the topics addressed in the documents.
Similarly to what we have done before, we are going to consider the topography of this second dataset, using its measures of proximity of among the documents as the features. To achieve this, we, again, are going to use T-SNE to reduce the dimensionality and apply Kmeans to cluster similar documents.
We prepare the vectors using the inferences of our trained model
# preparing the vectors to be used
model.random.seed(161803)
vectors = []
vectors_test = []
for doc in tqdm(train):
model.random.seed(161803)
vectors.append(model.infer_vector(doc.words))
for doc in tqdm(test):
model.random.seed(161803)
vectors_test.append(model.infer_vector(doc))100%|██████████| 1672/1672 [02:22<00:00, 11.73it/s]
100%|██████████| 418/418 [00:35<00:00, 11.89it/s]
Then we extract the features using T-SNE
# Create the model
tsne_model = TSNE(n_components=2, random_state=161803)
tsne_features = tsne_model.fit_transform(np.array(vectors))
tsne_features_test = tsne_model.fit_transform(np.array(vectors_test))Now we can take a look into the way the data is distributed in our dimension-reduced space.
# Plot the transformed data
plt.scatter(tsne_features[:,0], tsne_features[:,1], alpha=0.5)
plt.show()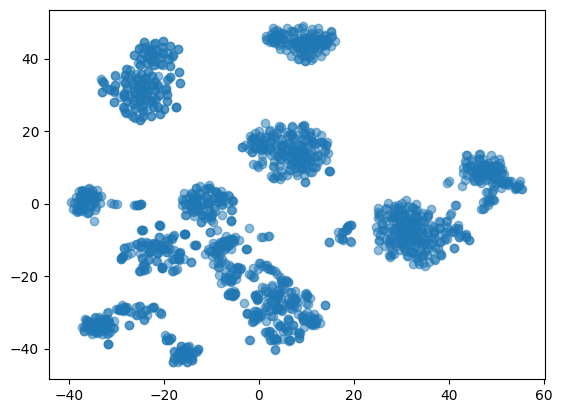
plt.scatter(tsne_features_test[:,0], tsne_features_test[:,1], alpha=0.5)
plt.show()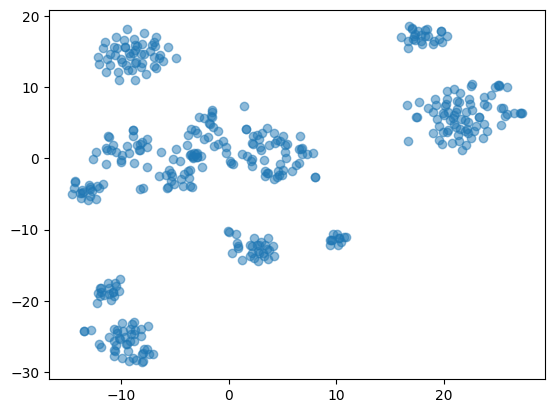
Both train and test sets have a more defined group of clusters. There are a bunch of observations in a not so well defined cluster in the center of both train and test sets. However, compared to the previous dataset, it is quite clear that clusters are more compact.
Let's proceed with the process of clustering to have a better understanding of the data.
We start by trying to see the best number of clusters to start with.
silhouette_analysis(tsne_features, min_k=2, max_k=30)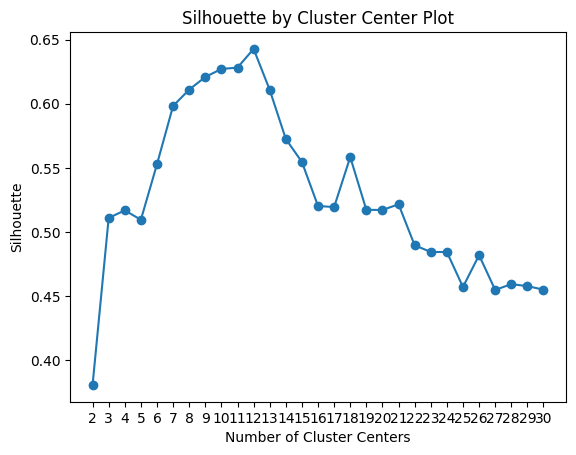
We can see two peaks on teh silhouette score, one with 9 clusters (about 0.64 of silhouette) and 12 clusters (a bit closer to 0.645). Again, we may consider the elbow method as a second way to decide the number of clusters.
elbow_method_analysis(tsne_features, max_k=30)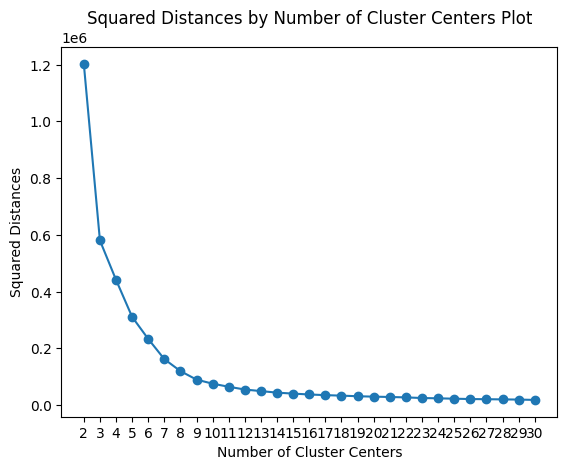
There is a sharper tendency break with the value of 9 clusters than with 12 clusters. Therefore we are going to pick the former - especially because the silhouette score doesn't change that much from 9 to 12 clusters).
NUM_CLUSTERS = 9labels = cluster_data(tsne_features, NUM_CLUSTERS)WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
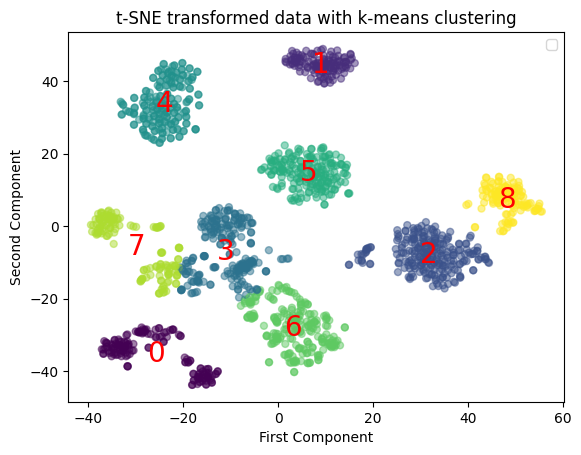
This time the clisters are quite well defined. Only cluster one of the clusters (Cluster 3, in this run) seems to be a bit indecisive about its elements beloging to neighboring clusters (6 and 7 in this run).
Let's inspect the content of the clusters a bit closer...
mapping = {label:np.where(labels == label)[0] for label in set(labels)}
print('Label \t# inst\t% Total')
for k, v in mapping.items():
print('{}\t{}\t{:.2f}'.format(k, len(v), len(v)/sum([len(item) for item in mapping.values()])))Label # inst % Total
0 151 0.09
1 128 0.08
2 249 0.15
3 228 0.14
4 213 0.13
5 203 0.12
6 233 0.14
7 140 0.08
8 127 0.08
Again, let's use WordClouds to take a look at the most relevant topics per cluster
clusters = {k:[train_data['tfidf_filtered_text'].iloc[idx] for idx in v] for k, v in mapping.items()}plot_clusters_into_word_clouds(clusters)100%|██████████| 9/9 [00:09<00:00, 1.01s/it]

All of the clusters seem to be consistent, having as most common the words pertaining to a single domain. However there is the weird occurence in one of the clusters (cluster 3 in this run) of a few words which may suggest something to be explored, such as "Paulo". We may inspect the clusters using topics extraxction to verify if this occurence is still visible.
generate_topics_from_clusters(clusters, stopwords=stopwords)#######################################################
# Topics in Cluster 0 #
#######################################################
Topic #1: maria, pedro, aé, taá, ixé, itá, maã, ana, ne, upé
Topic #2: sga, sg, diz, pla, ta, ir, pl, maã, mãe, br
Topic #3: nheengatú, br, nomes, verbos, sg, verbo, forma, pessoa, nome, fonologia
Topic #4: língua, nheengatú, rio, geral, português, fonologia, gramática, ainda, baixo, the
Topic #5: ua, itá, upé, aé, ma, ne, ixé, mu, ia, ta
-------------------------------------------------------
#######################################################
# Topics in Cluster 1 #
#######################################################
Topic #1: allah, vós, certo, fé, então, ratu, mensageiro, sobre, enquanto, dentre
Topic #2: certo, então, dia, senhor, ratu, senão, terra, allah, seguida, sobre
Topic #3: al, ratu, nome, deus, clemente, contra, senhor, homens, allah, então
Topic #4: então, vós, senhor, ambos, vosso, efeito, ratu, senão, haverá, cada
Topic #5: disse, certo, então, senhor, povo, moisés, disseram, allah, ratu, efeito
-------------------------------------------------------
#######################################################
# Topics in Cluster 2 #
#######################################################
Topic #1: disse, vossa, mercê, respondeu, senhor, porque, pois, senhora, deus, bem
Topic #2: la, el, en, mi, al, los, es, las, si, su
Topic #3: dom, quixote, cavaleiro, todos, história, havia, todo, cabeça, dois, parte
Topic #4: sancho, disse, pois, bem, quixote, respondeu, onde, porque, amo, pança
Topic #5: tão, porque, todos, disse, pois, assim, bem, onde, tudo, então
-------------------------------------------------------
#######################################################
# Topics in Cluster 3 #
#######################################################
Topic #1: vida, escola, pode, mundo, desenvolvimento, forma, criança, assim, sobre, homem
Topic #2: comportamento, análise, cliente, comportamentos, psicologia, pode, sobre, relação, forma, assim
Topic #3: psicologia, homem, social, capítulo, ciência, mundo, conhecimento, estudo, sobre, humano
Topic #4: paulo, sobre, psicologia, rio, família, in, livro, teoria, grupo, pessoas
Topic #5: of, and, the, in, to, comportamento, análise, psicologia, comportamental, social
-------------------------------------------------------
#######################################################
# Topics in Cluster 4 #
#######################################################
Topic #1: deus, porque, fiéis, quanto, porém, vós, tudo, mensageiro, sabei, bem
Topic #2: allah, porque, crentes, quanto, porém, vós, mensageiro, sabei, bem, tudo
Topic #3: senhor, dia, verdade, terra, pois, porém, tudo, quanto, dize, alcorão
Topic #4: al, alcorão, clemente, surata, nome, humanos, deus, todos, língua, ar
Topic #5: disse, senhor, povo, porque, moisés, porém, disseram, pois, então, verdade
-------------------------------------------------------
#######################################################
# Topics in Cluster 5 #
#######################################################
Topic #1: senhor, havia, sido, dia, haviam, povo, sobre, cristo, ainda, todos
Topic #2: pai, filho, deus, senhor, jesus, disse, cristo, nome, verdade, porque
Topic #3: jesus, havia, sido, homem, disse, ter, senhor, mulher, sobre, pois
Topic #4: capítulo, jesus, cristo, joão, senhor, morte, dia, grande, filho, pedro
Topic #5: deus, homem, assim, sobre, homens, todos, pode, cristo, poder, terra
-------------------------------------------------------
#######################################################
# Topics in Cluster 6 #
#######################################################
Topic #1: sal, ver, manteiga, bem, água, pimenta, molho, creme, mi, ingredientes
Topic #2: carne, corte, gordura, retire, pode, sabor, minutos, bem, ver, antes
Topic #3: massa, farinha, manteiga, água, trigo, deixe, açúcar, cm, sobre, pão
Topic #4: peixe, corte, ver, assar, cozinhar, fazer, papel, casca, óleo, frutas
Topic #5: unidade, colher, chá, sopa, sal, azeite, cebola, preparo, gosto, coloque
-------------------------------------------------------
#######################################################
# Topics in Cluster 7 #
#######################################################
Topic #1: of, the, and, in, nova, obra, to, psicologia, skinner, paulo
Topic #2: mente, skinner, ciência, comportamento, teoria, mundo, sobre, natureza, conhecimento, ponto
Topic #3: comportamento, análise, psicologia, história, estudo, palavras, et, pode, comportamentos, estímulos
Topic #4: verbal, resposta, skinner, estímulo, respostas, eventos, controle, sujeito, estímulos, pode
Topic #5: sono, durante, criança, psicologia, pais, análise, crianças, et, sobre, comportamentos
-------------------------------------------------------
#######################################################
# Topics in Cluster 8 #
#######################################################
Topic #1: vossa, mercê, senhor, disse, quixote, tão, cavaleiro, responde, cavaleiros, pois
Topic #2: sancho, quixote, responde, disse, porque, bem, amo, pode, ainda, assim
Topic #3: capítulo, quixote, la, onde, cavaleiro, outros, outras, conta, pança, escudeiro
Topic #4: tão, pode, bem, ainda, porque, ter, tudo, assim, amigo, dizer
Topic #5: disse, todos, porque, pai, pois, terra, logo, havia, bem, assim
-------------------------------------------------------
We confirmed that cluster 3 has some weird (though very low in relevance) words/topics. Let's make use of the additional information this dataset has about each observation, seeing how the different domains are distributed in the clusters.
def clusters_dist_to_dataframe(clusters_dist, aspect_name, percentage=False):
fields = list(set(sum([list(vals.keys()) for vals in clusters_dist.values()], [])))
fields.sort()
column_names = [aspect_name] + ['Cluster ' + str(i) for i in clusters_dist.keys()]
tablevalues = []
# Add rows to the table
for field in fields:
row = [field]
if not percentage: row.extend(clusters_dist[cluster].get(field, '') for cluster in clusters_dist.keys())
else:
percentages = []
for cluster in clusters_dist.keys():
val = clusters_dist[cluster].get(field, '')
if val != '':
val = '{:.2f}'.format((val / sum(clusters_dist[cluster].values())) * 100) + '%'
percentages.append(val)
row.extend(percentages)
tablevalues.append(row)
return pd.DataFrame(tablevalues, columns=column_names)clusters_categs = {k:[train_data['domain'].iloc[idx] for idx in v] for k, v in mapping.items()}
clusters_dist_domain = {cluster:{categ:clusters_categs[cluster].count(categ) for categ in set(clusters_categs[cluster])} for cluster in clusters_categs.keys()}
clusters_dist_to_dataframe(clusters_dist_domain, 'Domain', percentage=True)| Domain | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alcorao | 100.00% | 1.75% | 100.00% | ||||||
| 1 | cervantes | 100.00% | 1.75% | 100.00% | ||||||
| 2 | cristianismo | 19.30% | 100.00% | |||||||
| 3 | culinaria | 7.02% | 100.00% | |||||||
| 4 | nheengatu | 100.00% | 0.44% | |||||||
| 5 | psicologia | 69.74% | 100.00% |
clusters_dist_to_dataframe(clusters_dist_domain, 'Domain', percentage=False)| Domain | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alcorao | 128 | 4 | 213 | ||||||
| 1 | cervantes | 249 | 4 | 127 | ||||||
| 2 | cristianismo | 44 | 203 | |||||||
| 3 | culinaria | 16 | 233 | |||||||
| 4 | nheengatu | 151 | 1 | |||||||
| 5 | psicologia | 159 | 140 |
We can clearly see that cluster 3 is a miscellaneous amalgamation of psychololy (mostly) with judeochristianism and gastronomy. The other clusters are well defined and self contained.
However, it became also clear that some domains didn't stay in the same cluster. We had two distinct clusters for:
alcorao,cervantes, andpsicologiaGiven that we also have information about the books in our dataset, we may inspect how each book was present in each cluster.
clusters_categs = {k:[train_data['orig_book'].iloc[idx] for idx in v] for k, v in mapping.items()}
clusters_dist_book = {cluster:{categ:clusters_categs[cluster].count(categ) for categ in set(clusters_categs[cluster])} for cluster in clusters_categs.keys()}
clusters_dist_to_dataframe(clusters_dist_book, 'Orig. Book', percentage=True)| Orig. Book | Cluster 0 | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 | Cluster 7 | Cluster 8 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alcorao_1.pdf | 0.44% | 48.83% | |||||||
| 1 | alcorao_2.pdf | 1.32% | 51.17% | |||||||
| 2 | alcorao_3.pdf | 100.00% | ||||||||
| 3 | cervantes_1.pdf | 99.60% | 0.44% | 4.72% | ||||||
| 4 | cervantes_2.pdf | 0.40% | 1.32% | 95.28% | ||||||
| 5 | cristianismo_1.pdf | 0.44% | 100.00% | |||||||
| 6 | cristianismo_2.pdf | 18.86% | ||||||||
| 7 | culinaria_1.pdf | 3.07% | 7.73% | |||||||
| 8 | culinaria_2.pdf | 0.44% | 6.44% | |||||||
| 9 | culinaria_3.pdf | 0.88% | 6.01% | |||||||
| 10 | culinaria_4.pdf | 5.15% | ||||||||
| 11 | culinaria_5.pdf | 0.44% | ||||||||
| 12 | culinaria_6.pdf | 1.32% | 42.49% | |||||||
| 13 | culinaria_7.pdf | 0.88% | 32.19% | |||||||
| 14 | nheengatu_1.pdf | 63.58% | 0.44% | |||||||
| 15 | nheengatu_2.pdf | 17.88% | ||||||||
| 16 | nheengatu_3.pdf | 18.54% | ||||||||
| 17 | psicologia_1.pdf | 0.88% | 47.14% | |||||||
| 18 | psicologia_2.pdf | 22.37% | 52.14% | |||||||
| 19 | psicologia_3.pdf | 46.49% | 0.71% |
From the data above, we can take the following conclusions:
alcorao_3.pdf was different enough to be in its own
cluster, separated from the other books with muslim literature. We
regard this difference to the way the author decided to translate into
Portuguese. It doesn't contain a translation, but a translation of the
meaning (Tradução do Sentido) of the original content in
Arabic.psicologia_3.pdf also found it place in a cluster
different from the other files in the domain of psychology. After some
inspection, we found out that psicologia_3.pdf is a more
generalistic text on psychology as a whole, while the other files
addressed more specific niches of the field.cristianismo_2.pdf (The Holy Bible itself), instead of
being in the same cluster as cristianismo_1.pdf (which is a
commentary/treaty on the four gospels/New Testament) found its place in
the same cluster as psicologia_3.pdf.Only the domains culinaria and nheengatu
kept in a single cluster most of their contents, as visually represented
in the plot below.
import matplotlib.pyplot as plt
def plot_clusters_dist_piechart(clusters_dist):
# Create a grid of subplots
number_of_rows = (len(clusters_dist) + 1) // 2
fig, axes = plt.subplots(nrows=number_of_rows, ncols=2, figsize=(15, 20))
# Iterate through the axes and plot the images
for ax, cluster, data in zip(axes.flat, clusters_dist.keys(), clusters_dist.values()):
ax.pie(data.values(), labels=data.keys(), autopct='%1.1f%%', startangle=90)
ax.axis('equal')
ax.set_title(f'Cluster {cluster} Distribution')
# Adjust layout to prevent clipping of titles/labels
plt.tight_layout()
# Show the plot
plt.show()
plot_clusters_dist_piechart(clusters_dist_book)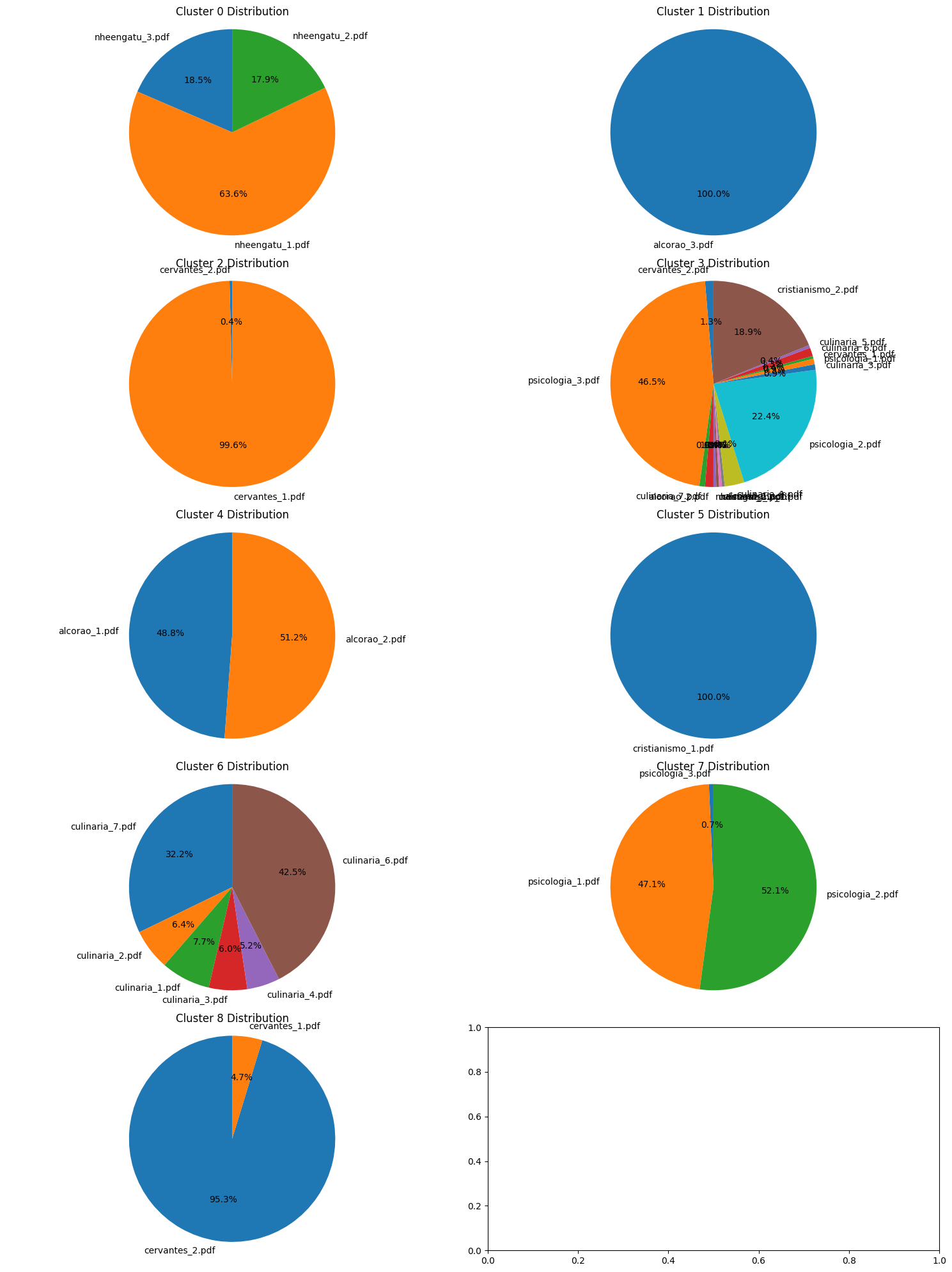
alert_me()After analyzing the behavior of the datasets, with the same methods, and taking into account that they yielded very different results, we may consider as certain the original hypothesis we had on the dataset with Legislative Text.
Even though the document set as a whole deals with a variety of topics, most of them are so similar in structure and contents that they are really close one to another. Their overall homogeneity makes them too related to be clustered.
At the same time, if we strip the whole dataset from the elements shared among the majority of the elements, the remaining information is so intrinsically particular to a single document (or a small group of them), that they are too heterogeneous to be effectively clustered.
Therefore, we might consider that, at least with the most basic approaches as this one, brought about in this activity, the feasibiliity of clustering these documents is questionable. However, with more evaluation, consideration of different and more elaborate approaches, it might be possible to achieve better results.
AL CORÃO. Al Corão. No Information about the
translator. Ebook available on http://www.dominiopublico.gov.br/download/texto/le000001.pdf.
Here referred to as alcorao_1.pdf
AL CORÃO. Os Significados dos Versículos do Alcorão
Sagrado. Translated by Samir El Hayek Goodword. India, Goodword
Books, First Edition, 2017. Here referred to as
alcorao_2.pdf
AL CORÃO. Tradução do Sentido do Nobre Al-Corão para a Língua
Portuguesa. Translated by Dr Helmi. Here referred to as
alcorao_3.pdf
BOCK, A. M. B.; FURTADO, O.; TEIXEIRA, M. L. T.
Psicologias: Uma introdução ao estudo da Psicologia.
São Paulo, 13a Edição, 1999. Here referred to as
psicologia_3.pdf
BÍBLIA. Santa Bíblia: Antigo e Novo Testamentos.
Tradução: João Ferreira de Almeida. LCC Publicações Eletrônicas, 2006,
eBooksBrasil.org. Here referred to as
cristianismo_2.pdf
CERVANTES, M. S., D. Quixote de La Mancha — Primeira
Parte. eBooksBrasil, 2005. Here referred to as
cervantes_2.pdf
CERVANTES, M. S., Dom Quixote de la Mancha,
Translated by Ernani Soo. Penguin-Companhia das Letras, São Paulo, 2012.
Here referred to as cervantes_1.pdf
HAYDU, V.; FORNAZARI, S.; ESTANISLAU, C. (org). Psicologia e
Análise do Comportamento: Conceituações e Aplicações à
Educação, Organizações, Saúde e Clínica. Londrina : UEL, 2014. Here
referred to as psicologia_2.pdf
TALMAGE, J. E., Jesus, O Cristo. A Igreja de Jesus
Cristo dos Santos dos Últimos Dias, São Paulo, 1964. Here referred to as
cristianismo_1.pdf
ZILIO, D. A natureza comportamental da mente:
behaviorismo radical e filosofia da mente [online]. São Paulo: Editora
UNESP, 2010. Here referred to as psicologia_1.pdf
%%shell
jupyter nbconvert --to html '/content/drive/MyDrive/Mestrado/PLN/NLP Assessment Activity: Doc2Vec'[NbConvertApp] Converting notebook /content/drive/MyDrive/Mestrado/PLN/NLP Assessment Activity: Doc2Vec to html
[NbConvertApp] Writing 2216089 bytes to /content/drive/MyDrive/Mestrado/PLN/NLP Assessment Activity: Doc2Ve.html